神经网络体系结构的主要类型
本课程主要介绍的内容是各种各样的神经网络,而这些神经网络根据神经元连接的方式大致可以划分成三种主要的体系结构
第一种结构是前馈神经网络(feed-forward neural networks)。这种结构是迄今为止实践中应用最多的结构,其第一层是输入,最后一层是输出,中间所有层都称为隐藏层。如果隐藏层层数大于1,那么得到的网络就称为“深度”神经网络。使用时,数据从输入层流入,沿着一个方向通过隐藏层,直到输出层。由于网络中各个神经元都使用了不同的非线性函数做激活函数(见上一讲中的“神经元模型”一节),来对输入进行处理,因此前一层原本相似的数据经过激活函数变换以后,在下一层可能就会变得不同;反之,原来不同的地方可能就会相似。典型的例子是语音识别中,需要不同说话人说的相同内容变得相似,同一说话人说的不同内容变得相异,因此非线性激活函数就起到了这样的作用
第二种结构是循环神经网络(recurrent neural networks, RNN)。这种结构比传统前馈神经网络更强大:对于某一个隐藏层神经元,其不一定非要连向下一层神经元,而是也可以连向同层中的其它神经元,即这种网络的连接图中可以有一个有向的环路。这意味着从某个神经元开始,沿着连接方向游走,最后可能会回到出发点。RNN可以表现出很复杂的动态性,因此比较难训练,但是目前研究人员已经找到了很多突破方法
RNN更像生物体中神经网络的结构,同时,它更适用于对序列建模。此时,隐藏层单元之间也会有连接,从表现形式上看,隐藏层之间的连接就像是一个随时间展开的,非常深的网络。此时每个时刻隐藏单元的状态都会决定下一个时刻隐藏单元的状态,只不过隐藏单元之间使用的权重矩阵是相同的,而深度前馈网络中各个隐藏层之间的权重矩阵是不同的。RNN具有在隐藏单元中长时间记忆信息的能力,在自然语言处理领域中用得非常多。例如Ilya Sutskever在ICML 2011上的论文Generating Text with Recurrent Neural Networks就使用了RNN来预测给定字符序列后的下一个字符。该工作使用英文维基中的文章作为训练材料,得到的模型可以产生出基本符合英语语法的段落
第三种结构是对称连接网络(symmetrically connected networks)。在RNN中,隐藏层神经元之间可以有一串沿时间线向前的连接,也可以有一串向后的连接,但是这两串连接使用的权重矩阵是不同的。对称连接网络也是有两串连接,但是这些连接是对称的,也就是它们的权重矩阵相同。没有隐藏层单元的对称连接网络称为Hopfield网,而带有隐藏层单元的称为玻尔兹曼机(Boltzmann machine)。对称连接网络比RNN更好分析,因为它们在能力上受到了一些限制,而且更符合能量函数。对称连接网络不能对环路建模
初代神经网络:感知机
(本章从本节开始的内容也可参考林轩田老师课程的笔记。需要注意的是,林课中标签集合\(\mathcal{Y} = \{-1, 1\}\),而本课使用的标签集合\(\mathcal{Y} = \{0, 1\}\))
本章的主角是感知机这种模型,它在20世纪60年代初期曾经红极一时,但是随着Minsky和Papert证明了它们能力上的限制以后就迅速衰落了下去
对于统计的模式识别问题,有一套比较标准的解决方案:首先,把原始输入向量转化成特征向量。这个阶段不涉及任何“学习”的内容,由开发人员通过直觉来手写代码完成。得到的特征可能有用,也可能没用,如果没用的话,再设法去产生新的特征来验证,这样最后肯定能够得到一组能用的特征向量。真正的学习阶段出现在确定各个特征的权重时。由于最后得到的是一个标量,因此每个特征的权重代表了该特征在多大程度上支持或者反对“输入数据属于要识别的模式”这个命题。确定权重以后,将所有特征加权求和,如果最后得到的值超过某个权重,就认为输入是目标类别的正例,反之则认为是负例。感知机是统计模式识别系统的一个例子,有多种变种,但是被Rosenblatt称为\(\alpha\)-感知机的模型大体遵循了这个过程:使用人工从输入获得的激活向量,学习出一个权重,将权重与激活向量求内积得到一个值,根据这个值与阈值的比较结果判定样本的类别
具体说来,感知机使用的是一个二元阈值神经元模型,这个模型在前一章曾经提到过。其表达形式如下: \[ z = b + \sum_i x_iw_i,\ y= \begin{cases}1 & {\rm if}\ z \ge 0 \\ 0 & {\rm otherwise}\end{cases} \] 由于偏置项可以看作是阈值的负数,为了不去为偏置项设置一个单独的学习策略,可以将输入做一个修改:在输入向量中增加一个维度,这个维度上的值永远是1,那么学到的权重向量在该维度上就是偏置值
对输入进行处理(加入常数项)后,就可以使用如下方法训练感知机:
感知机训练算法
随机初始化权重向量\(\bf w^{(0)}\),使用任意方法遍历全部样本,对每一个样本\({\bf x}_i\)观察输出,如果输出是正确的,略过,否则
- 如果真实标签是1而输出为0,则\({\bf w}^{(t+1)} = {\bf w}^{(t)} + {\bf x}_i\)
- 如果真实标签是0而输出为1,则\({\bf w}^{(t+1)} = {\bf w}^{(t)} - {\bf x}_i\)
重复上述过程,直到遍历过训练集所有样本而权重没有发生改变时,算法终止
感知机算法的一个很好的性质是,如果存在一个权重向量可以将所有样本正确分类,那么算法一定会终止且找出这个向量。然而,它的局限性也在于,如果对给定的训练样本不存在这样一个向量,算法就不能正常工作。事实上,这个向量存在与否,决定于使用了什么特征,而对很多问题很难找到良好的特征
感知机的几何意义
本节将在高维空间里讨论感知机的几何意义,同时要涉及到一些关于超平面的概念。尽管听上去比较复杂抽象,但是若把一个14维空间看成一个3维空间,超平面看成是一个2维平面,问题就好理解一些
首先来看权重值空间。这个空间里的每一个维度都对应权重向量的一个分量,而空间中的每个点都代表了某个可能的权重。假设沿用上一节的做法,不单独考虑阈值,那么每条输入数据就可以表示为一个穿过原点的超平面,权重在该超平面的某一侧。下图给出了一个示例
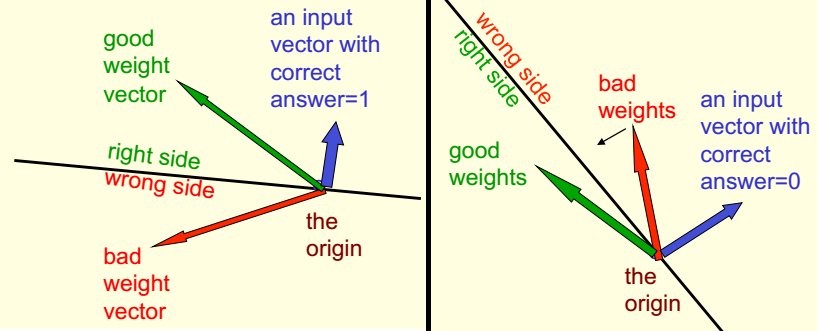
在图中,每个训练数据以蓝色的向量表示,其定义了一个超平面(以黑线表示),注意超平面与该训练数据所代表的向量总是正交的(即该训练数据是其定义的超平面的法向量)。对于上图左,输入样本为正例。如果权重向量与输入向量指向同样的方向(超平面的同一侧,上图左的绿色向量),此时两个向量的夹角是个锐角,内积的结果是正值。由于不考虑阈值,因此内积为正代表权重向量给出了正确的判断,即这个权重向量是好的。相反,对于上图左中的红色向量,其与输入向量的夹角是钝角,内积结果为负,意味着其将输入样本判定为负,所以是不好的向量。对于上图右,输入样本是负例,因此需要好的向量与输入向量夹角为钝角,指向相反的方向(即权重向量和输入向量指向超平面的两侧)
综上所述,对于任意给定的输入向量,只要某个权重向量指向了正确的方向,那么就能得到正确的答案。进一步地,如果在同一张图里同时画出正例和负例样本,会怎么样呢?
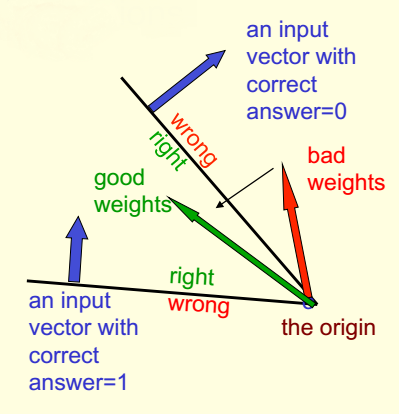
上图中,正例样本和负例样本确定的两个超平面又定义了一个锥体(cone),所有落在这个锥体中的权重向量对这两个样本都能给出正确的结果。这个例子可以容易地扩展到多个样本的情况——当然,有可能对于某个样本集,不存在可以将所有样本都正确分类的向量。但是如果这样的权重向量存在,它必然会存在于某个锥体中。此外,另一个需要注意的事实是,对于任意两个满足条件的权重向量(即这两个向量都在合适的锥体中),它们的均值也会满足最优条件。这意味着这个问题是凸的,而凸学习问题(凸优化问题)往往容易解决
为什么感知机算法能够工作
本节将(从几何的角度)证明为什么感知机算法能最终落入最优解的凸锥中(更理论的证明可以参看林轩田老师的课程笔记)。假设存在一个权重向量能够对训练集的所有样本正确分类,并称该向量为可行向量,以及当前向量错分了某个样本,记为错误向量,如下图所示
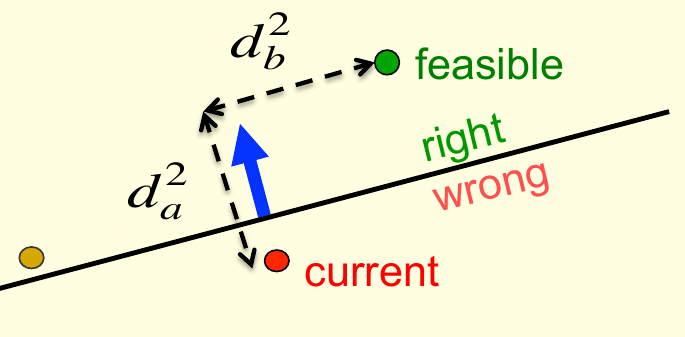
上图中,绿色的点代表理想的可行向量,红色的点代表当前的权重向量。由感知机算法的权重更新规则,当算法错分某个样例时,会让权重向量更靠近可行向量一些,因此可以得出当前权重向量与可行向量点的距离平方,其可以进一步分解为某个沿着超平面方向向量的长度平方与沿着超平面法向量方向的向量的长度平方的和,按照图中的记法,为\(d_a^2+d_b^2\)。更新权重以后,权重沿着蓝色箭头的方向移动了一点,因此\(d_a\)变小,\(d_b\)不变,权重可以向着可行向量逼近
但是有些情况是个例外:如果可行向量对应于图中金色的点,输入向量太大,那么当前权重移动就会过多,离可行向量更远。因此我们想定义更可行的权重向量,它不仅能分对所有训练样本,还能保证每个训练样本离它有一定距离(保持一定的边界),这个距离要至少等于定义了超平面的那个输入向量的长度,这样,就能保证感知机算法犯错时权重向量总是靠近可行向量了。因此在有限次犯错后,权重向量肯定会落在可行区间,如果这个区间存在
(感觉更严谨的证明还是得看林轩田老师课的笔记)
感知机算法的局限性
感知机的局限性主要来自于应用者所使用的特征。如果用的是对的特征,那几乎什么都能做;但是如果用的是错的特征,就会受到很大的限制
假设现在的数据集输入全都是0-1数组,那么最简单的做法是为数组的每种情况都创建一个特征,这样,对\(n\)位的数组,创建\(2^n\)个特征可以涵盖所有情形,理论上不会受到任何限制。但是实际上,这种方法很难泛化,因为看到的训练集很可能只是可能出现的所有情况的一个子集,如果测试时遇到了新不在这个子集里的特征组合,那么查表法就无法工作(回忆林课的例子,假设现在有3个特征位,一共有8种组合。即便我们知道了其中5种组合分别对应于正例还是负例,也无法确定剩下3种组合应该如何判定)
如果要使用感知机算法,对这类数据学习权重来判断正负例,事情也会不太简单。事实上,对某些非常简单的例子,感知机算法都无能为力。考虑如下问题:假设输入数据维度为2,每个维度的取值范围是0或者1,假设输入数据为 \[ (1,1) \rightarrow 1;\ \ (0, 0) \rightarrow 1 \\ (1,0) \rightarrow 0;\ \ (0, 1) \rightarrow 0 \] 即,如果两元素相同,则为正例;两元素相反,则为负例。对于这样的例子,感知机不能学习到权重。从代数的角度看,求解这个例子相当于求解如下四个不等式 \[ \begin{align*} &w_1 + w_2 \ge \theta,&&0 \ge \theta\\ &w_1 < \theta, && w_2< \theta \end{align*} \] 这四个不等式显然是不能同时成立的:由第二个不等式,\(\theta\)是非正数,又由第三个和第四个不等式,\(w_1, w_2\)是小于\(\theta\)的负数,它们的和肯定是个更小的负数,\(w_1 + w_2 < \min(w_1, w_2) < \theta\),与\(w_1 + w_2 \ge \theta\)是矛盾的
从几何的角度看,这个问题更为直观。对于上述问题,建立一个坐标系,横纵轴对应输入向量的两个维度,则这个空间中的每个点都可以对应于一个数据点。权重向量则在这个空间中定义了一个分离超平面,该平面垂直于权重向量指向的方向。此外,这里还考虑进了截距(偏置)的存在,因此分离超平面不应非得通过原点。对于前面给出的例子,可以做出下图
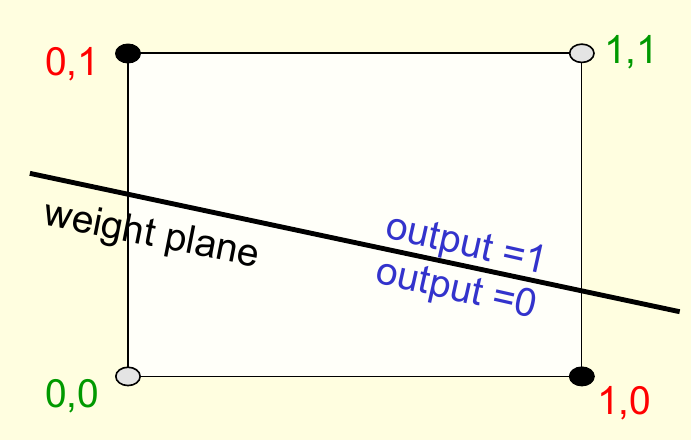
可以看到,对于这样的四个数据点,无法做出一条直线使得所有灰色的点在线的一侧,同时保证所有黑色的点在线的另一侧。对于这种无法使用超平面分离的例子,我们称其为线性不可分的。
对于其它例子,感知机也有不能判别的情况。考虑下面这个模式识别的例子:假设有一个长度为\(L\)像素的线段,其中一些像素点被染成了黑色。染色的方法遵循某些模式,如图所示
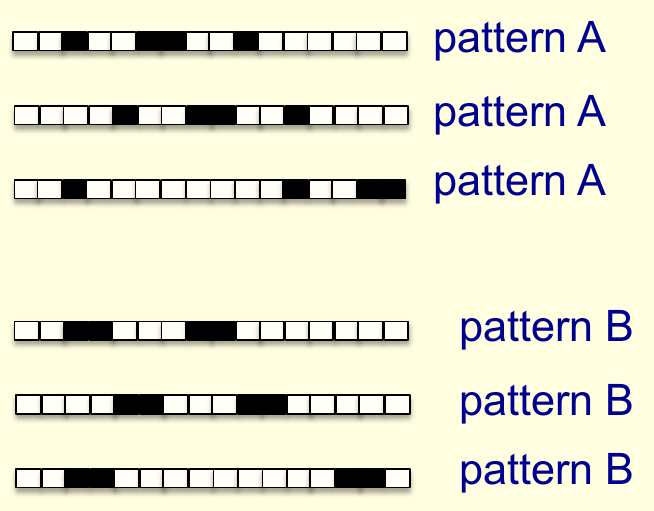
对于上图,模式A为1黑2白2黑2白1黑,模式B为2黑3白2黑。注意这里把这个线段看作是首尾连接的,因此模式A和B的第三种情况也都遵守各自的规则。而且,例子中两个模式虽然不同,但是其中黑色像素点的数量相同,都为4。假设只使用像素点是否为黑作为特征,能否用感知机区分这两种模式?答案是不能。因为对模式A,有四个点被染色(激活),感知机得到的得分是\(4\sum w_i\);而对模式B,也有四个点被激活,感知机得到的得分也是\(4\sum w_i\)。因此在这种情况下,感知机无法区分A和B。Minsky等人的著作也就是从这里入手对感知机进行批判的,因为模式识别就是要保证算法能够在模式经过变换以后仍然能够判断出模式是否相同,而这个实验证明感知机不能直接学习到“变换”。为了处理这些变换操作,感知机需要使用多个特征来意识到子模式的变换所带来的信息,而这种特征需要人手动编码来提供,并不是通过学习过程学到。在20世纪70年代,当时人们的结论是,感知机以及衍生出的神经网络都是不怎么有用的。而现在回头看,更正确的结论是,只有到神经网络能够学到如何检测特征,那才是真正的强大。不过人们花了将近20年来思考如何用神经网络检测特征
从这一讲可以得知,没有隐藏层单元的神经网络(即感知机)能力非常有限。而且,即便加入隐藏层单元,如果在这些单元只进行线性变化,意义也不大,因为最后还是一个线性模型,这种模型只有在我们手动喂进了正确的特征时才有用。真正需要的模型是多层含有自适应非线性隐藏单元的模型,但是这样问题就变成了我们应该如何训练这样的网络。事实上,学到隐藏单元的权重就是在学习特征,而这也就是真正的难点:没有人能直接告诉我们隐藏层应该干什么,它们什么时候应该活跃,什么时候不该活跃。没人能告诉我们特征选取器应该是什么样时,如何学习隐藏单元的权重,进而把隐藏单元转化成真正需要的特征选取器呢?
Frank Rosenblatt在20年代60年代初期编写了一本伟大的著作《神经动力学原理》,在这本书中,他描述了很多种不同的感知机模型。1969年,Minsky和Papert出版了《感知机》这本书,分析了感知机的能力和局限。然而,很多人却将本书中提出的局限扩大到了所有神经网络模型,甚至是整个人工智能领域。但实际上,感知机在今天仍然广泛应用于使用非常大特征向量的应用中
