为什么需要机器学习?
对于一些问题,例如在复杂环境里,如何在新的光源条件下识别三维物体,编写程序去解决这些问题本来就是非常困难的:我们也不知道我们的大脑到底是如何运作来识别它的,即便我们知道,写出来的程序可能也十分复杂。对于另外一些问题,例如判断某笔信用卡交易有多大概率是欺诈性的,可能无法给出简单有效的规则。要解决这样的问题,需要将很多种比较弱的规则组合起来。而且,所谓“道高一尺魔高一丈”,犯罪分子也会根据系统的判别手段,调整欺诈的方式,这就使得判别系统/程序也得随之变化
这些问题可以使用机器学习这一技术来解决:开发人员不再需要为每个特殊的任务编写程序,而是收集很多样本,这些样本针对给定的输入,会相应标记一个正确的输出。机器学习算法会接受这些样本,产生一个程序来完成指定的任务——这个产生的程序与传统的人工手写的程序不同,可能只包含一些数字。如果收集的数据是正确的,那么对于新来的,未在输入数据里出现的例子,程序也能正确处理;如果数据产生了变化(就像信用卡欺诈的例子里那样),开发人员也只需要使用新的数据进行训练,来对程序进行变化。在现阶段,使用机器做大量计算所花的钱比雇人为某个任务写代码的花费是要少一些的
典型的可以使用机器学习来解决的问题包括:
- 模式识别,例如识别物体、识别脸孔或识别所说的单词
- 异常识别,例如识别信用卡交易中的异常交易序列、在核电站识别传感器的异常读数。注意解决这样的问题有时甚至不需要明确地说明哪些值是正常的,哪些是异常的,而是完全由算法去发掘
- 预测,例如预测将来某一天股票的价格或者外汇汇率,以及用户对某部电影的评分
在这诸多问题中,本课将挑选一个作为一个典型样例贯穿始终。类比于遗传学中的工作,由于人们对果蝇的习性了解很多,而且果蝇繁殖速度很快,因此遗传学经常使用果蝇作为研究对象。本课所选的“果蝇”是MNIST数据库,这里面包含了很多人手写的数字。MNIST是公开的,可以被随意下载,而且使用MNIST作为训练数据可以很快训练一个中等大小的神经网络,此外,我们也了解其它很多机器学习算法在MNIST上的效果,因此MNIST是一个很好的例子

上图给出了MNIST数据集的一个片段,所有的手写数字已经按照进行了归类排序。也就是说,图中的所有数字先是所有0,再是所有1,以此类推,一直到9。以图中用绿框框起来的手写的2为例,如果被告知“这就是手写数字”,那么人们大概是能看出来这些数字是2的,但是并不能用一两句话说清楚这些图像为什么就是2。图中给出的这些数字相互之间形状差异很大,即便是做一些简单的变化(例如旋转)也很难让任意两个数字重叠在一起,因此使用模板来做判定是基本不可能的——这也就是为什么这个任务是一个很好的机器学习任务的原因
在MNIST之上,还有一个更大的数据集ImageNet。该数据集提供了130万张高分辨率的图片,算法的目标是将每张图片分到1000个分类中正确的那一个。2010年时,最好的系统的top 5 choices错误率为25%。2012年时,使用深度学习训练处的模型做到了20%。到了2015年,最好的算法在这项指标上已经可以达到3.8%,而多个深度神经网络的组合模型甚至可以达到3.08%(http://ischlag.github.io/2016/04/05/important-ILSVRC-achievements/)
此外,语音识别也是深度学习非常适用的一个场合。通常来讲,语音识别系统可以细分为三个阶段:
- 预处理阶段。在这个阶段,声波会被转化为一些声学系数组成的向量。通常情况下,每十毫秒的声波会被转化为一组向量
- 声学建模阶段。在这个阶段,会使用相邻的若干向量进行推测,猜测这些向量对应了什么音素
- 解码阶段。在这个阶段,将上一阶段做出的预测进行组合,拟合出的模型将输出说话人所说的内容文本
深度学习模型在这样的任务上取得的成绩是斐然的。对于TIMIT数据集,2012年之前最好的模型错误率是24.4%,而且需要对多个模型进行组合。2012年George Dahl和Abdel-rahman Mohamed的8层神经网络将错误率降低到了20.7%。这样的成绩也引起了微软研究院邓力的关注。对于其它语音识别任务,深度学习模型也能够取得比传统GMM模型更好的效果,而且训练时间更短
神经网络是什么?
前面提到的各种大放异彩的深度学习模型,被称之为“深度”的原因是其本质是叠加了很多层的神经网络。神经网络模型,其初始思想就是对生物的神经系统如何工作做一个模拟,所以这一节主要来对生物的神经系统做一个概述。了解生物神经元是如何计算的,有以下几点原因
- 可以了解大脑真正是如何工作的。大脑的工作原理非常复杂,而且当它被取出来时也就不工作了,因此需要使用计算机进行模拟
- 可以了解由神经元和它们之间自适应连接所启发的并行计算方式。这种计算方式与常见的串行计算很不相同。对于大脑很擅长的工作(例如视觉),使用这种计算方式可能能达到非常好的效果;但是对大脑不擅长的工作(例如计算23x71)就不适用了
- 大脑的工作原理可以启发研究人员发明一些新颖的机器学习算法来解决实际问题。尽管这些算法的原理可能并不同于大脑真正的工作原理,但是仍然会是有用的
神经系统的基本组成元素是皮层神经元(cortical neuron)。神经元由一个细胞体(cell body)和一根轴突(axon)组成,其中轴突末端会分叉。细胞体还会分出若干树突(dendritic),来从其它神经元获得输入。轴突与树突通常在突触(synapse)处交互,轴突中产生的冲动(spike)会导致电离子注入到突触后神经元,当足够的电离子流入以后,轴丘(axio hillock)会在突触产生流出的冲动,来对细胞膜(cell membrane)去极化(depolarize)。下图给出了神经元的一个示意图
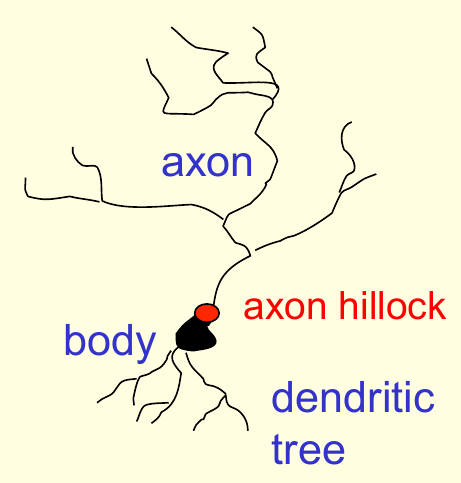
冲动随着轴突流动到达突触时,会导致突触小泡(vesicle)释放高浓度的化学传递物质。传递物质会沿着突触间隙(synaptic cleft)扩散至突触后神经元的细胞膜,吸附到膜中的受体(receptor),造成细胞膜形状的改变,产生若干小孔,使得特殊的离子可以进出。突触的功效性还可以随着突触小泡的数量和受体的数量变化。总体来看,突触是比较慢的,但是与RAM相比仍然有其优势:它们体积很小,功耗很低,而且可以根据局部的信号适应环境。但是它们具体是遵从何种规则来做出变化的呢?
每个神经元会从其它神经元那里获取到输入,它们之间通过冲动来进行交互。神经元的输入功效由突触的权重来控制,这些权重可以是正的,也可以是负的,而且这些权重是自适应的,因此整个网络可以适应不同的环境,完成不同的计算任务,例如辨识物体、理解语言、制定计划、控制身体等等。人身上大概有一千亿个神经元,每个神经元有一万个权重。这大量的权重可以在非常短时间内影响计算。
此外,神经元是模块化的,大脑皮层的不同部分有不同的功能,对大脑皮层不同区域的损伤会造成不同的后果,而正常人完成不同的任务时血液也会流向不同的区域。但是,皮层看上去又是相似的,如果在婴儿时期大脑受到了破坏,那么其它部分可能会承担被破坏部分的功能。例如如果在婴儿时期负责视觉的皮层遭到了破坏,大脑可能会把视觉任务重新分配给听觉皮层,在这样的刺激下,听觉皮层中会产生出视觉神经元,因此实际上有可能存在一个通用的学习方法。也就是说,皮层在形成的时候其用途是广泛的,但是随着经验的积累,不同区域的皮层会变得只处理某个特别的任务。如果使用类似的原理来计算,则可以兼顾速度、并发度和灵活性。传统的计算机通过存储顺序指令来获得这样的灵活性,但是这需要一个非常快的中央处理器来执行很长的计算序列
一些简单的神经元模型
本节介绍一些基本的神经元模型。尽管这些模型与真正的神经元工作原理相比简单得似乎不值一提,但是它们的能力已经足可以搭建起来一个神经网络模型,来解决一些有趣的机器学习问题
为了了解复杂的现象,一般总是要对目标做理想化才能建模。理想化的过程可以去掉繁复的枝叶:这些盘根错节的东西对理解主要原理是不必要的。理清主干以后,就可以使用数学手段,将目标系统与其它已经了解过的系统做类比,来理解主要原理。主要原理理解了以后,就可以方便地一点一点增加模型的复杂度,来让模型与现实更加贴近。当然,有时候去理解一些已经知道是错误的模型也是值得的,只要不要忘记这是一个错误的模型就行。例如,神经网络模型中神经元传递的通常是实数值而不是冲动,但是实践证明这种做法是有效的
神经网络中最简单的神经元是线性神经元。这种模型非常简单,但是计算能力有限。这种神经元的输出\(y\)由输入\(x_i\)的加权和再加上偏置\(b\)得到,即 \[ y = b+\sum_ix_iw_i \] 其中\(w_i\)是第\(i\)个输入\(x_i\)的权重
在此基础上,McCullock-Pitts在1943年提出了二元阈值神经元,其第一步还是要算出输入的加权和,然后,要将加权和与某个阈值作比较,如果超出该阈值,则发射一个冲动信号。原作者认为,冲动信号就像是某个谓词的真值,因此这里每个神经元就是将输入的真值做组合,输出自己所代表谓词的真值。二元阈值神经元有两种表示形式。一种是纯加权和的形式,并设定阈值为\(\theta\)。即 \[
\begin{align*}
z &= \sum_ix_iw_i,\ \ y = \begin{cases}1 & {\rm if\ }z \ge \theta \\ 0 & {\rm otherwise}\end{cases}
\end{align*}
\] 如果将阈值看作是负的偏置,即\(\theta = -b\),就可以写出与线性神经元类似的偏置+权重的形式,即 \[
z = b + \sum_i x_iw_i,\ \ y = \begin{cases}1 & {\rm if\ }z \ge 0 \\ 0 & {\rm otherwise}\end{cases}
\] Hinton将上述两种神经元进行了组合,得到了ReLU神经元(有时也称为线性阈值神经元)。这种方法仍然会计算输入的线性加权和,但是输出是所有输入的一个非线性函数。具体形式为 \[
z = b + \sum_i x_iw_i,\ \ y = \begin{cases}z & {\rm if\ }z \ge 0 \\ 0 & {\rm otherwise}\end{cases}
\] 本课中最常用的神经元是sigmoid神经元,该神经元也是实践中最常用的神经元,它给出的是输出是实数的,且图像平滑有界。这种神经元通常使用logistic函数,即 \[
z = b + \sum_i x_iw_i, \ \ y = \frac{1}{1+e^{-z}}
\] Logistic函数的好处是其导数的形式很漂亮,使学习过程变得容易。具体道理在第三讲会讲解
最后一种神经元是随机二元神经元。它使用的表达式与sigmoid神经元相同,不过把logistic函数的输出看作是短时间内产生冲动的概率。即,它的输出还是0或者1,但是是以概率\(P = 1/(1+e^{-z})\)输出1。类似的技巧可以用在ReLU上,此时神经元产生冲动的概率服从泊松分布
笔者注
上面使用删除线删除的内容是Hinton在视频中提到,但是现在不适用的内容。近几年,在深度学习中,ReLU神经元的使用要比sigmoid的使用多很多。记Sigmoid函数为\(\sigma(x)\),即 \[ \sigma(x) = \frac{1}{1+e^{-x}} \] 其导数(梯度)满足性质 \[ \sigma'(x) = \sigma(x)(1-\sigma(x)) \] 可知当\(x=0\)时,sigmoid函数的梯度达到最大值,仅为0.25。而当\(x\)很大或者很小时,该函数会接近1或者-1,此时称发生了饱和(saturation)现象(事实上,有\(\sigma(5) \approx 0.9933\))。在这种情况下,函数的梯度值接近0。当使用深度网络或者RNN时,由反向传播的理论,会出现多个梯度的连乘。而多个接近于0的数连成会快速逼近0,造成梯度消失,使得几乎就有没有信号通过神经元传到权重再到数据了。而且,如果初始化的矩阵随机得不好,权重过大,那么饱和会快速出现,模型基本学不到什么东西
对于ReLU而言,当\(x>0\)时,其激活函数\(x\)的导数为1,连乘不会逼近0,避免了梯度消失。此外,对于输入值为负的神经元,其梯度为0,不会参与训练,保证了神经网络的稀疏性,可以避免过拟合。最后,ReLU梯度的计算更加简单,只需要写一个if-else语句,而sigmoid函数的导数涉及到了浮点数计算,实际上还是麻烦的
在近年的实际应用中,另一种tanh神经元也受到了一定程度的重视。形式为 \[ z = b + \sum_i x_iw_i, \ \ y = \tanh(z) \] 事实上,\(\tanh\)函数可以由sigmoid函数经过一个简单变换得到。其与原始sigmoid函数相比最大的好处是其是零中心的(函数图像在0点中心对称),不过并没有解决在输入太大或太小时造成的梯度消失问题
关于学习的一个简单样例
本节将给出一个关于机器学习的例子,尽管使用的网络结构比较简单,但是它已经可以做一些手写数字识别的工作。这个网络只有两层:
- 输入层神经元表示原始图像的像素密度
- 输出层指出图像表示的是哪个数字
图像的每一个像素点,如果被染色,就相当于有了投票的权利。每个被染色的像素点可以给几种不同的数字投票,得票最多的数字获胜——因此,这个过程就好像是输出的若干个类别互相比赛
前面提到,神经网络中的参数其实就是各个输入所对应的权重,因此为了展示训练过程,一个重要的问题是如何把权重表示出来。直观的做法是写明每个像素点为每个类别贡献了多少权重,但是这样需要写成千上万行数字,因此退而求其次,可以使用颜色来代表权重的大小和正负。对于某个给定的类别(这里是数字),如果一个像素点的颜色越浅,则代表该点贡献了一个越大的正权重;如果颜色越深,则代表该点贡献了一个越小的负权重
学习的方法设定为,首先,将所有像素点对所有类别贡献的权重随机初始化一个小值,然后对每个给定的手写数字图像中被染色的像素点:
- 增大其对正确分类的权重
- 减小其对网络所猜测的类别的权重
这种做法可以达到一个微妙的平衡:如果神经网络给出了正确的预测,那么该像素点对正确类别的权重贡献先增后减,相互抵消;但是如果给出了错误的预测,那么该像素点对正确类别的权重增大,对错误类别的权重减小。下图给出了刚刚初始化时和使用若干图片训练后的权重示意


尽管网络已经展现出了学习能力,而且效果还不错,但是它仍然有不足。本质上,它学到的其实是每个数字的一个手写模板。当来到一个新的输入时,对这个输入,用学到的10个模板挨个匹配,哪个匹配得最吻合,就认为写的是哪个数字。但是这个模板并不能完美匹配所有手写的数字图像。例如,对于下面的例子,无法找到一个模板,使得其可以辨识出所有2,同时又不会误把3当成2。因此,还是需要更复杂的网络模型

学习的三种类型
机器学习任务总体来讲可以分为三种类型
有监督学习
有监督学习的形式是,给定一个输入向量\(\bf x\),学习预测一个输出\(t\)。根据输出的形式,有监督学习又可以细分为两个子类别
- 回归:目标输出是一个实数,或者实数向量。例如预测之后6个月的股票价格、明天中午的气温等
- 分类:目标输出是一个类别标签,例如手写数字识别
进行有监督学习的典型过程通常是,首先选择一类模型\(y = f({\bf x}; {\bf W})\),它接受输入向量\(\bf x\),使用相关参数\(\bf W\),得到最后的输出\(y\)。模型这里也可以看作是一种映射,是输入到输出经由\(\bf W\)作用的映射。因此,学习的核心就是调整这些参数\(\bf W\),使得模型输出\(y\)与期望输出\(t\)之间的差距尽可能小。对于回归问题,这个差距的衡量方法通常是\(\frac{1}{2}(y-t)^2\) 。而对分类问题,存在更合理也更有效的衡量方式,之后会讲到
强化学习
强化学习的输出是一个动作,或者一串动作序列。这里也存在监督性的信号,不过只是不定时出现的一些奖励(或惩罚)。因此,强化学习的目标是选择最合适的动作来最大化将来可能获得的奖励的期望和——通常情况下,对每个奖励会设置一个跟时间相关的衰减因子,这样越后面的奖励加权后的重要性越小,使得模型不用考虑太远的将来
强化学习是一件比较难的事情,因为奖励通常都不会马上得到,所以模型并不知道是否走在了正确的道路上,而且奖励只是一个标量,本身提供的信息也有限
强化学习难以学到成百万的参数,通常是几十到几千个。但是其它两种学习形式不会有这样的限制
无监督学习
无监督学习的目的是要发现输入数据一个良好的内部表现形式。在将近40年的时间里,无监督学习在机器学习这个圈子里基本是处于被忽视的状态,一些广泛使用的关于“机器学习”的定义甚至实际上把这种问题排除掉了,而很多研究者认为只有聚类才是无监督学习唯一的表现形式
造成这种现象的原因之一是,很难一句两句话说清楚无监督学习的目标究竟是什么。大致来看,可以列举出如下几类目标
- 为输入数据创造一种内部表示形式,用于之后的有监督学习或强化学习
- 为输入数据提供一种紧凑、低维的表示方法,例如PCA
- 以学到的特征这一形式,为输入提供一种经济的高维表示方法
- 找到输入中一些合理的类簇
本次课程的前一半主要讲授有监督学习问题,后一半主要讲授无监督学习问题,而强化学习不在本次课大纲之内(笔者注:不过近几年深度强化学习也受到了越来越多的重视)
