机器学习模型的正则化是一个老生常谈的问题,毕竟模型训练出来的目的是让它在未知数据上表现良好,而不是死记硬背已有的数据——就像我们准备高考的时候大量刷题不是为了能在高考时遇见自己做过的题,而是为了能运用已有知识做出新题(当然咯,碰上是一件好事,但是这不是目标。况且以一般人的记忆力,遇到旧题还是会忘的,这个时候考试体验就更差了……)。而神经网络(尤其是比较深的神经网络)其模型复杂度会更高,因此过拟合的风险会更大,也就更有必要采取一些正则化手段,使得模型有更好的泛化能力。本节介绍的泛化手段基本均来自于花书第7章,不过会有详略之分——一些想法比较直接,或者已经介绍过很多遍的,就不会再浪费笔墨了。此外,以下方法由于各种原因,在这里略过
- 作为约束的范数惩罚(7.2节)。好像并不常用
- 噪声鲁棒性,向权重加入噪声(7.5节)。用得也不多了
- 半监督学习(7.6节)。展开可能能写出一篇文章……
- 多任务学习(7.7节)。在NLP里展开几乎必定能写出一篇文章……
- 参数绑定和参数共享(7.9节)。书里都说了最佳范例就是CNN,个人感觉RNN也包含类似思想
- 稀疏表示(7.10节)。神经元稀疏可以用ReLU做到,强制隐层稀疏好像用得不多了
- 对抗训练(7.13节)。展开可能能写出一篇文章……
- 切面距离、正切传播和流形正切分类器(7.14节)。基本没人用了……
因此以下主要整理一些常见的方法
数据增强
模型不能泛化的表现是在各种数据集上有比较大的方差,而这种现象出现的原因有一种可能是数据集里数据太“纯”,以至于模型没有看到一些只出现在验证集和测试集里的数据模式。解决方法是对输入数据做一些增强:普适的方法是增加一些噪声(常见的是加入高斯噪声),而对于与图像相关的问题,可能平移几个像素点、旋转图像、缩放图像、裁剪图像等都是有效的。需要注意的这种变换不能改变类别,比如OCR任务需要认识到“b“和”d“的区别,以及”6“和”9“的区别,此时水平翻转和旋转180°就不是合适的数据增强方式
不过在NLP领域,似乎缺少一些通用的数据增强手段——对不同的具体任务,可能需要一种具体的方法。例如,对于机器翻译,可以使用back translation的方法[Sennrich2015]。其它一些文章采用了同义词替换的方法:[Wang2015]是对给定的某个单词,在训练出的词向量里选择k个距离最近的词做替换,而[Zhang2015]则是使用词典做同义词替换
参数范数惩罚
对模型参数施加\(L^2\)范数惩罚使得不重要的参数接近于0,或者施加\(L^1\)范数惩罚淘汰不重要的特征让解变得稀疏,已经是介绍过很多次的正则化方法了,因此这里对概念不多做介绍,仅对花书中的一些重要结论做一记录
\(L^2\)正则化
假设原始目标函数为\(J(\boldsymbol{w}; \boldsymbol{X}, \boldsymbol{y})\),那么加入\(L^2\)正则化以后的目标函数改变为 \[ \tilde{J}(\boldsymbol{w}; \boldsymbol{X},\boldsymbol{y}) = \frac{\alpha}{2}\boldsymbol{w}^\mathsf{T}\boldsymbol{w} + J(\boldsymbol{w}; \boldsymbol{X},\boldsymbol{y}) \] 与之对应的梯度为 \[ \nabla_{\boldsymbol{w}}\tilde{J}(\boldsymbol{w}; \boldsymbol{X},\boldsymbol{y}) = \alpha \boldsymbol{w} + \nabla_{\boldsymbol{w}}J(\boldsymbol{w}; \boldsymbol{X},\boldsymbol{y}) \] 记\(\boldsymbol{w}^\ast = \mathop{\rm arg\ min}_{\boldsymbol{w}}J(\boldsymbol{w})\),并在\(\boldsymbol{w}^\ast\)的邻域内对\(J\)做二次近似,则 \[ \hat{J}(\boldsymbol{w}) = J(\boldsymbol{w}^\ast) + \frac{1}{2}(\boldsymbol{w}-\boldsymbol{w}^\ast)^\mathsf{T}\boldsymbol{H}(\boldsymbol{w}-\boldsymbol{w}^\ast) \] 其中\(\boldsymbol{H}\)是\(J\)在\(\boldsymbol{w}^\ast\)处计算的关于\(\boldsymbol{w}\)的Hessian矩阵。上式的梯度为 \[ \nabla_\boldsymbol{w}\hat{J}(\boldsymbol{w}) = \boldsymbol{H}(\boldsymbol{w}-\boldsymbol{w}^\ast) \] 因此新目标函数\(\tilde{J}\)的解\(\tilde{\boldsymbol{w}}\)满足 \[ \alpha\tilde{\boldsymbol{w}} + \boldsymbol{H}(\tilde{\boldsymbol{w}} - \boldsymbol{w}^\ast) = 0 \] 解得 \[ \tilde{\boldsymbol{w}} = (\boldsymbol{H} + \alpha\boldsymbol{I})^{-1}\boldsymbol{Hw}^\ast \] 由于\(\boldsymbol{H}\)是实对称矩阵,因此可以将其分解为一个对角矩阵\(\boldsymbol{\Lambda}\)和一组正交向量的标准正交基\(\boldsymbol{Q}\)(证明),并且有\(\boldsymbol{H} = \boldsymbol{Q\Lambda Q}^\mathsf{T}\)。代入上式,有 \[ \begin{aligned} \tilde{\boldsymbol{w}} &= (\boldsymbol{Q\Lambda Q}^\mathsf{T}+\alpha\boldsymbol{I})^{-1}\boldsymbol{Q\Lambda Q}^\mathsf{T}\boldsymbol{w}^\ast \\ &= [\boldsymbol{Q}(\boldsymbol{\Lambda}+\alpha\boldsymbol{I})\boldsymbol{Q}^\mathsf{T}]^{-1}\boldsymbol{Q\Lambda Q}^\mathsf{T}\boldsymbol{w}^\ast \\ &= \boldsymbol{Q}(\boldsymbol{\Lambda} + \alpha\boldsymbol{I})^{-1}\boldsymbol{\Lambda Q}^\mathsf{T}\boldsymbol{w}^\ast \tag{1} \end{aligned} \] 因此\(L^2\)正则的意义是沿着由\(\boldsymbol{H}\)的特征向量定义的轴缩放\(\boldsymbol{w}^\ast\)。更具体地,对\(\boldsymbol{w}^\ast\)的第\(i\)个分量\(w^\ast_i\),缩放系数为\(\frac{\lambda_i}{\lambda_i + \alpha}\),其中\(\lambda_i\)是\(\boldsymbol{H}\)的第\(i\)个特征值。对于\(\boldsymbol{H}\),其在有助于减小目标函数的方向上特征值大,在无助于减小目标函数的方向上特征值小,因此对\(\boldsymbol{w}^\ast\)来说不重要的分量会被显著缩小。假设正则项系数\(\alpha\)设为100,而且对某些方向\(\lambda_i <\!\!< \alpha\),那么\(w_i^\ast\)就会是原来的百分之一
在神经网络里,\(L^2\)正则通常也被称为权重衰减法
\(L^1\)正则化
对模型参数的\(L^1\)正则化被定义为 \[ \Omega(\boldsymbol{w}) = \|\boldsymbol{w}\|_1 = \sum_{i}|w_i| \] 与\(L^2\)正则化类似的,假设原始目标函数为\(J(\boldsymbol{w}; \boldsymbol{X}, \boldsymbol{y})\),那么加入\(L^1\)正则化以后的目标函数改变为 \[ \tilde{J}(\boldsymbol{w}; \boldsymbol{X},\boldsymbol{y}) =\alpha\|\boldsymbol{w}\|_1 + J(\boldsymbol{w}; \boldsymbol{X},\boldsymbol{y}) \] 与之对应的梯度为 \[ \nabla_{\boldsymbol{w}}\tilde{J}(\boldsymbol{w}; \boldsymbol{X},\boldsymbol{y}) = \alpha {\rm sign}(\boldsymbol{w}) + \nabla_{\boldsymbol{w}}J(\boldsymbol{w}; \boldsymbol{X},\boldsymbol{y}) \] 记\(\boldsymbol{w}^\ast = \mathop{\rm arg\ min}_{\boldsymbol{w}}J(\boldsymbol{w})\),简化假设\(\boldsymbol{H}\)是对角的,且\(H_{i,i} > 0\)(这个假设在线性回归问题中,若数据已被预处理,去除了输入特征之间的相关性,则假设成立)。在\(\boldsymbol{w}^\ast\)的邻域内对\(\tilde{J}\)做二次近似,则 \[ \hat{J}(\boldsymbol{w}) = J(\boldsymbol{w}^\ast) + \sum_i \left[\frac{1}{2}H_{i,i}(w_i - w_i^\ast)^2 + \alpha|w_i|\right] \] 上式右侧只有求和项与\(w_i\)有关,记为\(f(w_i)\)。\(f\)可以重写为 \[ f(w_i) = \frac{1}{2}H_{i,i}(w_i - w_i^\ast)^2 + \alpha {\rm sign}(w_i)\cdot w_i \] 令\(f'(w_i) = 0\),得到 \[ w_i = w_i^\ast - \frac{\alpha}{H_{i,i}}{\rm sign}(w_i) \] 因此最优的\(w_i\)有 \[ f(w_i) = \frac{\alpha^2}{2H_{i,i}} + \alpha|w_i| \] 又 \[ f(0) = \frac{1}{2}H_{i,i}{w_i^\ast}^2 + \alpha|w_i| \] 可知当\(w_i^\ast < \alpha/H_{i,i}\)时,0是极值点。又\(w_i^\ast = {\rm sign}(w_i^\ast)\cdot |w_i^\ast|\),因此当\(w_i\)取如下值时,最小化\(\hat{J}\) \[ w_i = {\rm sign}(w_i^\ast)\max\left\{|w_i^\ast| - \frac{\alpha}{H_{i,i}}, 0\right\} \] 对每个\(i\),假设\(w_i^\ast > 0\),有两种情况。一种是\(w_i^\ast \le \alpha / H_{i,i}\),此时最好的\(w_i\)为0;另一种\(w_i^\ast > \alpha / H_{i,i}\),这个参数还会被保留,因此\(L^1\)正则化会产生更稀疏的解
在TensorFlow中使用参数范数惩罚
在TensorFlow中,若要使用参数范数惩罚,通常是在定义损失函数时手动加上正则化项,例如(代码片段取自HAR-stacked-residual-bidir-LSTMs)
1 | l2 = lam * sum( |
注意这里的lam是上述推导里正则化系数\(\alpha\)的倒数
提前终止
方法概览
假设训练一个表示能力很强的模型,很有可能出现这样的情况:模型在训练集上的损失值一直下降,但是在验证集上先下降后上升。一种自然的想法是返回使验证集误差最低的参数设置,保存使验证误差最低的模型。由于通常来讲验证集与测试集分布相同,而且不参与训练,因此使验证误差最低的模型,很大可能也会使测试误差最低。这种方法称为提前终止法。提前终止法可以说是深度学习里最简单的正则化方法,实现也很简单,几乎不需要对训练过程做什么改动
由于提前终止法需要一部分数据做验证集,因此有一部分数据没有参与训练。为了更好地利用这些数据,需要使用所有数据重新训练。书里给出了两种方法:一种是重新初始化模型,然后用所有数据训第一轮训练的那么多步数;另一种是保持参数不变,继续训练,直到低于第一轮模型得到的损失值。两种方法各有各的问题,需要在实践中根据实际情况适当调整,而且在数据量太大,训练集规模远大于验证集规模时,验证集是否需要参与训练个人觉得也不是非常重要,影响不大
提前终止与\(L^2\)正则的关系
如果使用平方误差做误差函数,模型设定为简单的线性模型,使用普通的梯度下降法,则可以说明提前终止相当于\(L^2\)正则化。假设参数里没有偏置项,最佳值仍然为\(\boldsymbol{w}^\ast\),在\(\boldsymbol{w}^\ast\)的邻域内对\(J\)做二次近似,则 \[ \hat{J}(\boldsymbol{w}) = J(\boldsymbol{w}^\ast) + \frac{1}{2}(\boldsymbol{w}-\boldsymbol{w}^\ast)^\mathsf{T}\boldsymbol{H}(\boldsymbol{w}-\boldsymbol{w}^\ast) \] 其中\(\boldsymbol{H}\)是\(J\)在\(\boldsymbol{w}^\ast\)处计算的关于\(\boldsymbol{w}\)的Hessian矩阵。上式的梯度为 \[ \nabla_\boldsymbol{w}\hat{J}(\boldsymbol{w}) = \boldsymbol{H}(\boldsymbol{w}-\boldsymbol{w}^\ast) \] 假设学习率为\(\eta\),训练步数为\(t\),\(\boldsymbol{w}\)初始化为\(\boldsymbol{0}\)(尽管在神经网络里不能这么做,但是普通线性模型是可以的),分析\(\hat{J}\)上的梯度下降可以近似研究\(J\)上的梯度下降 \[ \begin{aligned} \boldsymbol{w}^{(t)} &= \boldsymbol{w}^{(t-1)} - \eta\nabla_{\boldsymbol{w}}\hat{J}(\boldsymbol{w}^{(t-1)}) \\ &= \boldsymbol{w}^{(t-1)} - \eta \boldsymbol{H}(\boldsymbol{w}^{(t-1)}-\boldsymbol{w}^\ast) \\ \boldsymbol{w}^{(t)} - \boldsymbol{w}^\ast &= (\boldsymbol{I}-\eta\boldsymbol{H})(\boldsymbol{w}^{(t-1)}-\boldsymbol{w}^\ast) \end{aligned} \] 将\(\boldsymbol{H}\)做特征分解\(\boldsymbol{H} = \boldsymbol{Q\Lambda Q}^\mathsf{T}\),代入上式,并两边同时左乘\(\boldsymbol{Q}^\mathsf{T}\),有 \[ \boldsymbol{Q}^\mathsf{T}(\boldsymbol{w}^{(t)}-\boldsymbol{w}^\ast) = (\boldsymbol{I} - \eta \boldsymbol{\Lambda})\boldsymbol{Q}^\mathsf{T}(\boldsymbol{w}^{(t-1)}-\boldsymbol{w}^\ast) \] 将\(\boldsymbol{Q}^{\mathsf{T}}(\boldsymbol{w}^{(t)}- \boldsymbol{w}^\ast)\)记为\(\boldsymbol{a}^{(t)}\),则 \[ \boldsymbol{a}^{(t)} = (\boldsymbol{I} - \eta\boldsymbol{\Lambda})\boldsymbol{a}^{(t-1)} \] 是一个等比数列,因此有 \[ \boldsymbol{a}^{(t)} = (\boldsymbol{I}-\eta\boldsymbol{\Lambda})^t\boldsymbol{a}^{(0)} \] 带回\(\boldsymbol{a}^{(t)}\)的定义,有 \[ \boldsymbol{Q}^{\mathsf{T}}(\boldsymbol{w}^{(t)}-\boldsymbol{w}^\ast) = (\boldsymbol{I}-\eta \boldsymbol{\Lambda})^t\boldsymbol{Q}^\mathsf{T}(-\boldsymbol{w}^\ast) \] 整理可得 \[ \boldsymbol{Q}^\mathsf{T}\boldsymbol{w}^{(t)} = [\boldsymbol{I}-(\boldsymbol{I}-\eta\boldsymbol{\Lambda})^t]\boldsymbol{Q}^\mathsf{T}\boldsymbol{w}^\ast \tag{2} \] 前面介绍\(L^2\)正则化时有个式子(1): \[ \tilde{\boldsymbol{w}} = \boldsymbol{Q}(\boldsymbol{\Lambda} + \alpha\boldsymbol{I})^{-1}\boldsymbol{\Lambda Q}^\mathsf{T}\boldsymbol{w}^\ast \] 两边左乘\(\boldsymbol{Q}^\mathsf{T}\),有 \[ \boldsymbol{Q}^\mathsf{T}\tilde{\boldsymbol{w}} = (\boldsymbol{\Lambda} + \alpha\boldsymbol{I})^{-1}\boldsymbol{\Lambda Q}^\mathsf{T}\boldsymbol{w}^\ast \] 由于\((\boldsymbol{\Lambda} + \alpha\boldsymbol{I})^{-1}\boldsymbol{\Lambda} + (\boldsymbol{\Lambda} + \alpha\boldsymbol{I})^{-1}\alpha = \boldsymbol{I}\),因此上式可以写为 \[ \boldsymbol{Q}^\mathsf{T}\tilde{\boldsymbol{w}} = [\boldsymbol{I} - (\boldsymbol{\Lambda} + \alpha\boldsymbol{I})^{-1}\alpha] \boldsymbol{Q}^\mathsf{T}\boldsymbol{w}^\ast\tag{3} \] 将(3)式与(2)式比较,可以发现,如果满足 \[ (\boldsymbol{I}-\eta\boldsymbol{\Lambda})^t = (\boldsymbol{\Lambda} + \alpha\boldsymbol{I})^{-1}\alpha \] 则提前终止与\(L^2\)可以看作是等价的。如果将上式两边取对数,做\(\log(1+x)\)的级数展开(\(\log(1+x) = x - \frac{x^2}{2} + \frac{x^3}{3} - \frac{x^4}{4} + \ldots\)),则可以得出结论:如果所有\(\lambda_i\)都是小的,满足\(\eta \lambda_i <\!\!< 1\)且\(\lambda_i /\alpha <\!\!< 1\),有 \[ t \approx \frac{1}{\eta \alpha},\ \ \ \ \ \alpha\approx\frac{1}{\eta t} \] 即在满足所有假设的情况下,训练迭代次数\(t\)起着和\(L^2\)参数成反比的作用
集成方法
集成方法概览
模型组合,或者称“集成学习”(ensemble learning),其核心思想是通过结合几个模型来降低泛化误差,因为不同的模型通常不会在测试集上产生完全相同的误差,或者说,它们产生的误差可以相互抵消掉
假设有\(k\)个回归模型,假设每个模型\(i\)在每个例子上误差是\(\epsilon_i\),这个误差服从均值\(\mathbb{E}[\epsilon_i] = 0\),方差\({\rm Var}[\epsilon_i] = \mathbb{E}[\epsilon_i^2] =v\)且协方差\(\mathbb{E}[\epsilon_i\epsilon_j] =c\)的多维正态分布。模型集成(通常是平均所有被集成模型的预测结果)得到的平均误差是\(\frac{1}{k}\sum_i \epsilon_i\),集成预测器的平方误差的期望是 \[ \begin{aligned} \mathbb{E}\left[\left(\frac{1}{k}\sum_i \epsilon_i\right)^2\right] &= \frac{1}{k^2}\mathbb{E}\left[\sum_i \left(\epsilon_i^2 + \sum_{j\not= i}\epsilon_i\epsilon_j\right)\right] \\ &= \frac{1}{k}v + \frac{k-1}{k}c \end{aligned} \] 假设所有模型误差完全相关,\(c=v\),上式结果是\(v\),与之前没有变化,模型平均没有什么帮助,但是也没有扯后腿;假设所有模型误差完全不相关,\(c=0\),那么平方误差的期望仅仅为\(v/k\),因此模型越多,集成规模越大,平方误差的期望就会越小。这说明如果各个成员的误差是独立的,集成将显著提高模型效果
常见的模型集成方法包括
- 装袋法(bagging),核心思想是对\(N\)个样本组成的测试集做\(k\)次有放回采样(bootstrap),训练\(k\)个模型,对它们的预测结果求平均。具体可参考哥大机器学习讲义:随机森林和台大机器学习讲义:装袋法
- 提升法(boosting),核心思想是训练\(k\)个比较弱的基分类器,对每个基分类器,着重使用前面分类器效果不好的数据做训练。具体可参考哥大机器学习讲义:Boosting和台大机器学习讲义:自适应提升算法
- 堆叠法(stacking)。具体做法是将训练集划分为两个不相交的集合,用第一部分数据训练基分类器,将这些基分类器在第二部分数据上做推断,然后将推断结果作为输入,正确标签做输出,训练一个更高级分类器。堆叠法通常会使用各种非常不一样的分类器(例如SVM、LR等等混杂)(Ensemble Learning)
对于神经网络,即便其结构相同,由于权重初始化往往是从某个分布中随机抽样取值,每个batch选取的数据可能不一样,以及其它超参数设置不同,使用同一个训练集训练出的不同模型往往就有部分独立的误差,可以做集成
常见的集成方法一般包括投票(常见于分类问题)、对结果求平均等等。对于NMT等seq2seq任务,在解码的时候通常使用beam search,此时模型集成的方法通常是将各个子模型给出的各单词得分做一个平均,取出top k结果,然后将这k个结果发送给各个子模型做下一步搜索。这种集成过程比较复杂,在TensorFlow里也不是特别容易实现(例如OpenNMT-tf就没有实现这个过程,目前只在OpenNMT-py里用PyTorch实现了)
参数平均
对于深度学习,有一个更加方便普适,易于实现的集成方法:每隔若干个step就保存一个检查点checkpoint,然后将每个检查点的权重加起来求平均,即对参数求平均。需要注意的是,参数平均要求被平均的模型至少有同样的结构和同样的随机初始化参数(不只是随机分布要相同,连随机的结果都要相同!),甚至初始若干个训练步骤都要相同。此时独立初始化的模型反而不能用作参数平均的输入
参数平均的思想在[Junczys-Dowmunt2016]中首先被验证有效,在[Izmailov2018]中得到了理论说明。简而言之,在若干简化条件下,使用恒定学习率运行SGD算法,等效于从一个期望为最佳参数(使损失函数取得最小值),协方差由学习率控制的正态分布中随机抽样的过程。SGD得到的解倾向于分布在一个平坦的局部极值区域(而不是一个点),因此将不同时间步得到的参数求平均会将最后得到的解落入到这个极值区域的内部,更接近最优解。下图给出了在CIFAR-100上训练ResNet-164(在预训练模型基础上微调)得到的误差函数表面,损失函数使用的是交叉熵函数,并采用了正则化。
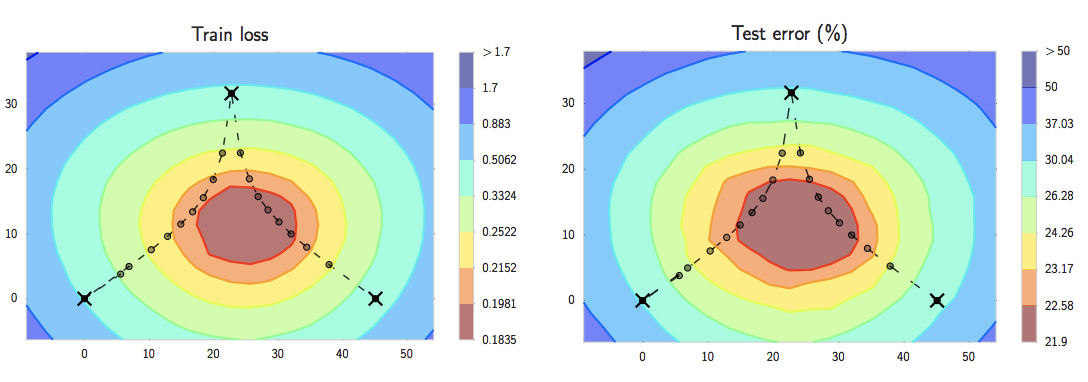
其中三个黑叉代表了微调开始、中期和结束时得到的参数位置。文章也采取了最近新提出的学习率调整策略(周期性调整学习率,学习率先变小再变大)做了同样的实验,得到了类似效果(不过新策略得到的三个点比固定学习率得到的点要明显靠近中心很多)
另一个值得注意的现象是,同一个模型的训练误差平面和测试误差平面形状相似,但不能完全对齐。下图给出了使用SGD在CIFAR-100上经过125个epoch训练ResNet-164得到的训练误差平面和测试误差平面,\(w_{\rm SGD}\)是SGD给出的最优解,\(w_{\rm SWA}\)是参数平均得到的解。可以看到,参数平均得到的解尽管在训练集上效果不那么好,但是有更强的泛化能力
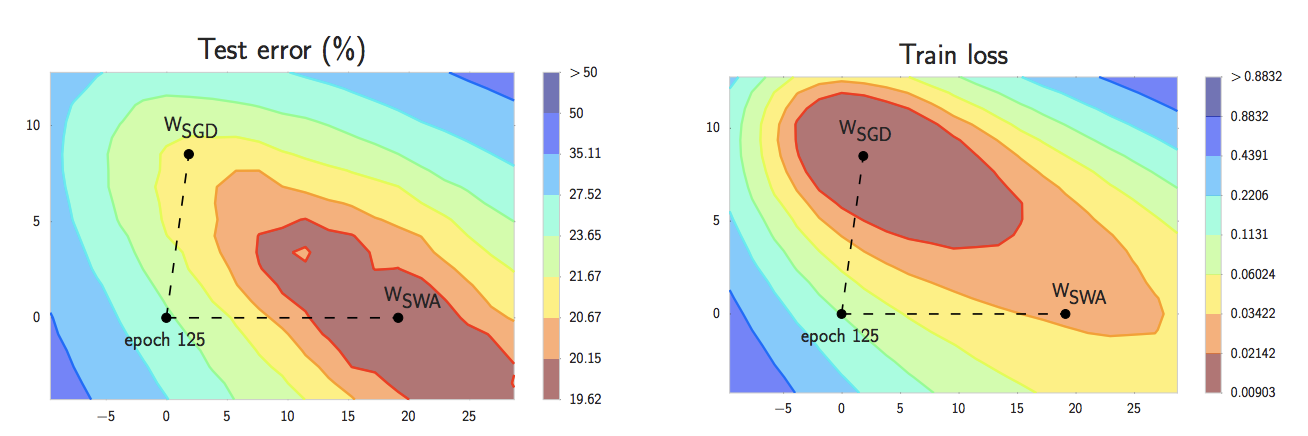
参数平均是一种非常高效的模型集成方法,它不需要额外时间训练若干个模型,也不需要在推断时花费多余的时间产生若干个结果。此外,其实现也非常简单,可以参考OpenNMT-tf的实现
Dropout
原理
在计算资源无限的前提下,要正则化一个固定大小的模型,最好方法是对模型所有可能的参数组合都算出各自的预测值,然后对预测值做加权平均,其中权重是给定训练数据后每组参数组合的后验概率。这种也是模型集成的方法,但是要完全达到这个目的,需要训练指数多个模型,代价太大了
Dropout的目的是防止过拟合,以及对“组合指数多个不同神经网络”这一遥不可及的目标给出一个近似而且有效的方法。其基本思想比较直观,即在训练时的每一批次,对网络中的每个神经元(输入神经元和隐藏神经元都可以)独立地以概率\(p\)保留之。如果随机数落到了\([1-p, 1)\)的区间,就将它连同其入边和出边一起临时删掉。这样,对神经网络做dropout类似于从原始网络抽样出一个“苗条版”的子网络,因此对有\(n\)个节点的网络,可以看做其包含了\(2^n\)个子网络(每个节点都可能被保留/丢弃),对其使用dropout训练就像是训练了\(2^n\)个权重共享的小网络
在测试时,很难让所有小网络都给出预测值,然后做加权平均,不过可以使用一种方法来取得近似的效果,就是在测试/推断时使用没有dropout的网络,只不过每个节点出边的权重都乘以\(p\),使得节点在训练时输出的期望与测试时的实际输出相匹配,以达到聚合模型的目的
Dropout这种思想的提出还受到了生物进化过程中有性繁殖这一过程的启发。因为在有性繁殖的过程中,父代个体的基因只有一般可能性会传给子代(而且可能还会变异),这就使得每个基因都要有一定鲁棒性,能力够强,能够跟其他随机一组基因很好地合作,不能每时每刻都依赖很多个同伴。类似地,使用dropout得到的每个隐藏神经元必须可以与随机分配的其它单元都能很好合作,能靠自己创造有用的特征,而不是依赖其它单元纠正它的错误。或者说,dropout更像是从一些成功的阴谋活动中吸取到了经验:每5个人完成一个小的阴谋,一共完成10个,总容易过让50个人一起完成一个大的阴谋
Dropout的形式化描述比较简洁。假设神经网络共有\(L\)个隐藏层,编号\(l \in \{1, \ldots , L\}\)。\(\boldsymbol{z}^{(l)}\)是第\(l\)层的输入向量,\(\boldsymbol{y}^{(l)}\)是第\(l\)层的输出向量(\(\boldsymbol{y}^{(0)} = \boldsymbol{x}\)是整个网络的输入)。\(\boldsymbol{W}^{(l)}\)和\(\boldsymbol{b}^{(l)}\)是第\(l\)层的权重和偏置,对\(l \in \{0, \ldots, L-1\}\)的每个节点\(i\),普通的前向传播有 \[ \begin{aligned} z_i^{(l+1)} &= \boldsymbol{w}_i^{(l+1)}\boldsymbol{y}^{l}+b_i^{(l+1)} \\ y_i^{(l+1)} &= f(z_i^{(l+1)}) \end{aligned} \] 其中\(f\)是激活函数。加入dropout以后,传播操作变为 \[ \begin{aligned} r_j^{(l)} &\sim {\rm Bernoulli}(p) \\ \tilde{\boldsymbol{y}}^{(l)} &= {\bf r}^{(l)} \otimes \boldsymbol{y}^{(l)} \\ z_i^{(l+1)} &= \boldsymbol{w}_i^{(l+1)}\tilde{\boldsymbol{y}}^{l}+b_i^{(l+1)} \\ y_i^{(l+1)} &= f(z_i^{(l+1)}) \end{aligned} \] 在测试/推断时,有 \[ \boldsymbol{W}_{\rm test}^{(l)} = p\boldsymbol{W}^{(l)} \] 原始论文推荐的参数是对隐藏节点,\(p\)设为0.5;对输入节点,设为0.8。此外,原始论文推荐将dropout和参数范数限制一起使用(即在优化时加上\(\|\boldsymbol{w}\| \le c\)的限制),不过现在(2018年)已经很少有人这么提了。另外有一些文章指出dropout在线性模型上可以起到L2正则化的效果,尽管花书指出这种推理不适用于神经网络,但是最新的文章 [Hara2016] 仍然(从效果上)对这个结论给予了支持。需要注意的是,尽管dropout在大多数网络上都有效,但是它不适用于规模比较小的网络
实现与使用
TF在实现dropout时,没有使用原始的dropout方法,而是使用了一种称为”inverted dropout“的技巧:训练时,所有没有被丢弃掉的神经元权重都除以\(p\),这样测试时就不需要修改网络的权重了。具体实现在tf.nn.dropout中,伪代码如下
1 | def dropout(x, p): |
应用时,在构建计算图的代码里,通常使用placeholder来接收外部传进来的keep_prob值(因为训练时和推断时的keep_prob值不同,推断时keep_prob值必须为1——这是一个很容易被忽视的地方!)
1 | with graph.as_default(): |
使用高阶API,例如Estimator时,建议使用tf.layers.dropout。它实际使用了keras对dropout的封装,可以通过开关判断是否需要dropout,所以与ModeKeys搭配使用尤其好,例如
1 | dense = tf.layers.dense(inputs=x, units=1024, activation=tf.nn.relu, name='dense') |
批归一化
Ioffe和Szegedy两人在[Ioffe2015]中对神经网络难以训练的原因提出了一个新的猜想:每一层的输入都由前面所有层的参数共同决定,因此随着网络的变深,一点小的变化也会被一直放大,即各层的输入所属的分布会发生变化,称为经历了“共变量偏移”(covariate shift)。将每一层输入的分布固定住可以让训练过程变得更有效:假设神经网络使用sigmoid函数作为激活函数\(g\),根据前面提到过多次的结论,当某一层的输入\(x\)的绝对值很大时,会有\(g'(x) \rightarrow 0\),发生梯度消失,训练变慢。但是这个\(x\)由前面所有层的参数算出来,因此参数发生变化以后\(x\)向饱和区域内移动的可能性是很大的。尽管这种情况可以通过使用ReLU激活或者好的初始化方法(见前一篇文章)来缓解,但是如果能让输入的分布保持稳定,也可以加速训练过程。文章称这种在训练过程中内部结点分布发生变化的现象为“内部共变量偏移”(internal convariate shift),并提出了一种减少这种偏移现象的方法——批归一化(batch normalization)
原理
批归一化操作的思想一部分来源于“白化”(whitening)操作,不过白化只是将神经网络的整体输入归一化,使其均值为0方差为1,而批归一化是对每一层的输入都如此做。但是,如果归一化参数是在梯度下降过程之外计算,会导致参数一直涨而损失值变化不大的情况,因为优化过程“不知道”归一化已经发生。所以正确的对策是让网络产生的激活值总是满足期望的分布,然而,对每一层的输入都做白化,会导致大量的计算而且可能不是处处可导
批归一化对此作了两个关键简化
不是联合白化输入和输出,而是对每个特征标量独立归一化。假设某一层的输入\(\boldsymbol{x}\)有\(d\)个维度,\(\boldsymbol{x} = \left(x^{(1)}, \ldots , x^{(d)}\right)\),则对每个维度都做如下归一化 \[ \hat{x}^{(k)} = \frac{x^{(k)} - {\rm E}[x^{(k)}]}{\sqrt{ {\rm Var}[x^{(k)}]}} \] 其中期望和方差是在整个训练集上求得。注意这个操作会改变这一层所能提取的特征,例如如果激活函数是sigmoid,那么做这个变换以后会把输入都集中在非饱和区域,因此需要保证这样的变化可以表示恒等变化。为了做到这一点,需要对每个激活值\(x^{(k)}\)引入一对变量\(\gamma^{(k)}\)和\(\beta^{(k)}\),前者用来缩放,后者用来偏移。这两个变量也是通过训练学到,它们的作用的是保持网络的表示能力
由于神经网络通常都是使用小批量SGD做优化,很难得到整个数据集的均值和方差,因此批归一化做了一个近似:使用每个小批量的均值和方差近似整个数据集的对应指标
由于对于特征\(x^{(k)}, k \in \{1, \ldots, d\}\),归一化都是各自独立的,因此对某个特征\(x^{(k)}\),可以简记为\(x\)。假设对由\(m\)条数据组成的某个小批量数据集\(\mathcal{B} = \{x_{1\ldots m}\}\),归一化得到\(\hat{x}_{1\ldots m}\),线性转换的结果为\(y_{1\ldots m}\),称变换\({\rm BN}_{\gamma, \beta}:x_{1\ldots m} \rightarrow y_{1\ldots m}\)为批归一化变换,具体算法如下图所示,其中\(\epsilon\)用来维持算法的数值稳定性

每个归一化后的激活值\(\hat{x}^{(k)}\)都可以看作是对下个子网络的输入,该子网络包括两个部分,先是线性变换\(y^{(k)}\),然后是原始网络的其它处理过程
上图的算法是在前向传播时计算。在反向传播时,损失函数\(L\)的梯度也可以相应使用链式法则算出 \[ \begin{aligned} \frac{\partial L}{\partial \gamma} &= \sum_{i=1}^m \frac{\partial L}{\partial y_i} \cdot \hat{x}_i \\ \frac{\partial L}{\partial \beta} &= \sum_{i=1}^m \frac{\partial L}{\partial y_i} \\ \frac{\partial L}{\partial \hat{x}_i} &= \frac{\partial L}{\partial y_i}\cdot \gamma \\ \frac{\partial L}{\partial \sigma_{\mathcal{B}}^2} &= \sum_{i=1}^m \left(\frac{\partial L}{\partial \hat{x}_i} \cdot \frac{\partial \hat{x}_i}{\partial \sigma^2_{\mathcal{B}}}\right) \\ &= \sum_{i=1}^m \frac{\partial L}{\partial \hat{x}_i} \cdot (x_i - \mu_{\mathcal{B}})\cdot \left(-\frac{1}{2}\right)(\sigma^2_{\mathcal{B}} + \epsilon)^{-\frac{3}{2}} \\ \frac{\partial L}{\partial \mu_{\mathcal{B}}} &= \sum_{i=1}^m\left(\frac{\partial L}{\partial \hat{x}_i} \cdot \frac{\partial \hat{x}_i}{\partial \mu_{\mathcal{B}}}\right) + \frac{\partial L}{\partial \sigma^2_{\mathcal{B}}}\cdot \frac{\partial \sigma_{\mathcal{B}}^2}{\partial \mu_{\mathcal{B}}} \\ &= \left(\sum_{i=1}^m\frac{\partial L}{\partial \hat{x}_i} \cdot \frac{-1}{\sqrt{\sigma^2_{\mathcal{B}} + \epsilon}}\right) + \frac{\partial L}{\partial \sigma^2_{\mathcal{B}}} \cdot \frac{1}{m}\sum_{i=1}^m-2(x_i-\mu_{\mathcal{B}}) \\ &= \sum_{i=1}^m\frac{\partial L}{\partial \hat{x}_i} \cdot \frac{-1}{\sqrt{\sigma^2_{\mathcal{B}} + \epsilon}}\ \ \ \ \left(\because \sum_{i=1}^m \mu_{\mathcal{B}} = m\cdot\frac{1}{m} \sum_{i=1}^mx_i = \sum_{i=1}^m x_i\right) \\ \frac{\partial L}{\partial x_i} &= \frac{\partial L}{\partial \hat{x}_i} \cdot \frac{\partial \hat{x}_i}{\partial x_i} + \frac{\partial L}{\partial \mu_{\mathcal{B}}}\cdot \frac{\partial \mu_{\mathcal{B}}}{\partial x_i} + \frac{\partial L}{\partial \sigma_{\mathcal{B}}^2}\cdot \frac{\partial \sigma_{\mathcal{B}}^2}{\partial x_i} \\ &= \frac{\partial L}{\partial \hat{x}_i} \cdot (\sigma^2 + \epsilon)^{-\frac{1}{2}} + \frac{\partial L}{\partial \mu_{\mathcal{B}}}\cdot\frac{1}{m} + \frac{\partial L}{\partial \sigma^2_{\mathcal{B}}} \cdot \frac{2}{m}(x_i-\mu_\mathcal{B}) \\ &= \frac{\partial L}{\partial \hat{x}_i} \cdot (\sigma^2 + \epsilon)^{-\frac{1}{2}} -\frac{1}{m}(\sigma^2_{\mathcal{B}} + \epsilon)^{-\frac{1}{2}}\left(\sum_{j=1}^m\frac{\partial L}{\partial \hat{x}_j}\right) -\frac{1}{m}(\sigma^2 + \epsilon)^{-\frac{1}{2}}\cdot \frac{x_i - \mu_{\mathcal{B}}}{\sqrt{\sigma^2_{\mathcal{B}} + \epsilon}} \cdot \sum_{j=1}^m 2\cdot\frac{\partial L}{\partial \hat{x}_j}\cdot(x_j-\mu_{\mathcal{B}}) \cdot \frac{1}{2} \cdot (\sigma^2 + \epsilon)^{-\frac{1}{2}} \\ &= \frac{\partial L}{\partial \hat{x}_i} \cdot (\sigma^2 + \epsilon)^{-\frac{1}{2}} -\frac{1}{m}(\sigma^2_{\mathcal{B}} + \epsilon)^{-\frac{1}{2}}\left(\sum_{j=1}^m\frac{\partial L}{\partial \hat{x}_j}\right) -\frac{1}{m}(\sigma^2 + \epsilon)^{-\frac{1}{2}}\cdot \hat{x}_i\cdot\left(\sum_{i=1}^m\frac{\partial L}{\partial \hat{x}_j}\cdot \hat{x}_j\right) \\ &= \frac{1}{m}(\sigma^2 + \epsilon)^{-\frac{1}{2}}\left(\frac{m\partial L}{\partial \hat{x}_i} - \sum_{j=1}^m\frac{\partial L}{\partial \hat{x}_j} - \hat{x}_i\sum_{i=1}^m\frac{\partial L}{\partial \hat{x}_j}\cdot\hat{x}_j\right) \end{aligned} \] 也就是说,批归一化变换是可导的变换,即随着模型的训练过程,每一层所使用的输入都会努力减小内部共线性偏移,训练可以加速
真正应用时,是对激活前的值做批归一化。即对某些层,如果原来接收的是\(x\),现在改为接收\({\rm BN}(x)\)。推断时,按照道理来讲,所有需要被批归一化的激活值都应该使用整个数据集的均值和方差做归一化操作,但是计算整个数据集的统计量可能比较耗时,所以可以使用滑动均值来做(这块实际做法和原文所说的做法感觉有差异,以实际做法为准),即对每个小批量数据,以如下方法估计整个样本的期望\(\hat{ {\rm E}}[x]\)和方差\(\widehat{ {\rm Var}}[x]\): \[ \begin{aligned} \hat{ {\rm E}}[x] &\leftarrow \alpha \hat{ {\rm E}}[x] + (1-\alpha)\mu_{\mathcal{B}} \\ \widehat{ {\rm Var}}[x] &\leftarrow \alpha \widehat{ {\rm Var}}[x] + (1-\alpha)\sigma_{\mathcal{B}}^2 \\ \end{aligned} \] 通常\(\alpha\)取0.9,也被称为“动量”(momentum,与前面介绍的动量法梯度下降有点不谋而合)
此外,假设原来要激活的值是\(\boldsymbol{Wu} + \boldsymbol{b}\),由于批归一化的\(\beta\)替代了\(\boldsymbol{b}\)原来的作用,因此可以将偏置项略去。也就是原来的\(\boldsymbol{z} = g(\boldsymbol{Wu}+\boldsymbol{b})\)被替换成\(\boldsymbol{z} = g({\rm BN}(\boldsymbol{Wu}))\),其中\(g\)是激活函数。再次提醒这里\(\rm BN\)是对每个特征维度做,学到的\(\gamma^{(k)}\)和\(\beta^{(k)}\)也是应用在各个特征维度上
需要注意的是,对于卷积神经网络,为了保证满足卷积操作的性质,需要对同一卷积核内的所有神经元做相同的归一化操作,因此对卷积核大小为\(p \times q\)的网络来说,此时小批量样本数的大小\(m' = |\mathcal{B}| = mpq\),\(\gamma^{(k)}\)和\(\beta^{(k)}\)也是适用于每个卷积核,而不是单独的神经元
使用批归一化的网络可以使用大一点的学习率训练,因为对标量\(a\),容易验证\({\rm BN}(\boldsymbol{Wu}) = {\rm BN}((a\boldsymbol{W})\boldsymbol{u})\),因此 \[ \begin{aligned} \frac{\partial {\rm BN}((a\boldsymbol{W})\boldsymbol{u})}{\partial \boldsymbol{u}} &= \frac{\partial {\rm BN}(\boldsymbol{W}\boldsymbol{u})}{\partial \boldsymbol{u}} \\ \frac{\partial {\rm BN}((a\boldsymbol{W})\boldsymbol{u})}{\partial (a\boldsymbol{W})} &= \frac{1}{a} \cdot \frac{\partial {\rm BN}(\boldsymbol{W}\boldsymbol{u})}{\partial \boldsymbol{W}} \end{aligned} \] 即学习率越大,梯度会越小,参数增长反而更稳定
此外,批归一化方法也是一种正则化的手段。简单地讲,可以看做是向样本中添加了噪声,因为每个隐藏单元都缩放了一个随机值\(\sigma_{\mathcal{B}}\),也减去了一个随机值\(\mu_\mathcal{B}\)(Ian Goodfellow的回答)。香港中文大学的研究者对其中原理做了更深入的分析,有兴趣的读者可以访问文章的OpenReview版本了解更多
使用与实现
TensorFlow为批归一化提供了若干种实现手段,包括
tf.nn.batch_normalization,是一个封装层级比较低的操作符。调用者需要自己手动处理mean和variance张量tf.nn.fused_batch_norm,跟上一个操作符平级,针对CNN里常用到的四维输入张量做了优化tf.contrib.layers.batch_norm,一个比较老的实现。传言TF2.0要舍弃掉contrib包,所以这个方法不建议用tf.nn.batch_norm_with_global_normalization,也是要废弃的实现了tf.layers.batch_normalization,是对第一个操作的高层封装,主要包括了以下几项支持:- 会自己维护滑动均值和方差
- 会根据输入决定是否调用fused版本(也算是封装了
tf.nn.fused_batch_norm) - 支持virtual batch[Salimans2016b]。virtual batch主要在GAN上使用,为了解决每个批量数据里每个样本\(\boldsymbol{x}\)都依赖于其它输入的问题
- 支持批量重归一化(batch renormalization)[Ioffe2017]。该方法主要是引入一个新的线性变换来逼近数据的真实分布,在批数据量小或数据来源非独立同分布时比较有效
推荐使用tf.layers.batch_normalization
真正使用时,批归一化通常在激活函数之前(如果是CNN,一般是在卷积之后,激活之前),示例代码如下
1 | is_training = tf.placeholder(tf.bool) |
需要注意的是,该方法内部维护的moving_mean和moving_variance(实际上底层是某个keras.layers.BatchNormalization类对象维护的成员变量)需要在训练时被更新,而更新操作符在tf.GraphKeys.UPDATE_OPS中,因此需要加到train_op的依赖里,并且在获取UPDATE_OPS集合之前加入batch_normalization这个操作符,即
1 | conv1_bn = tf.layers.batch_normalization(...) |
否则两个滑动统计量不会被正确更新
调用tf.layers.batch_normalization方法时,实际上是新建了一个tensorflow.python.layers.BatchNormalization类的对象,然后调用apply方法。该类有如下继承关系
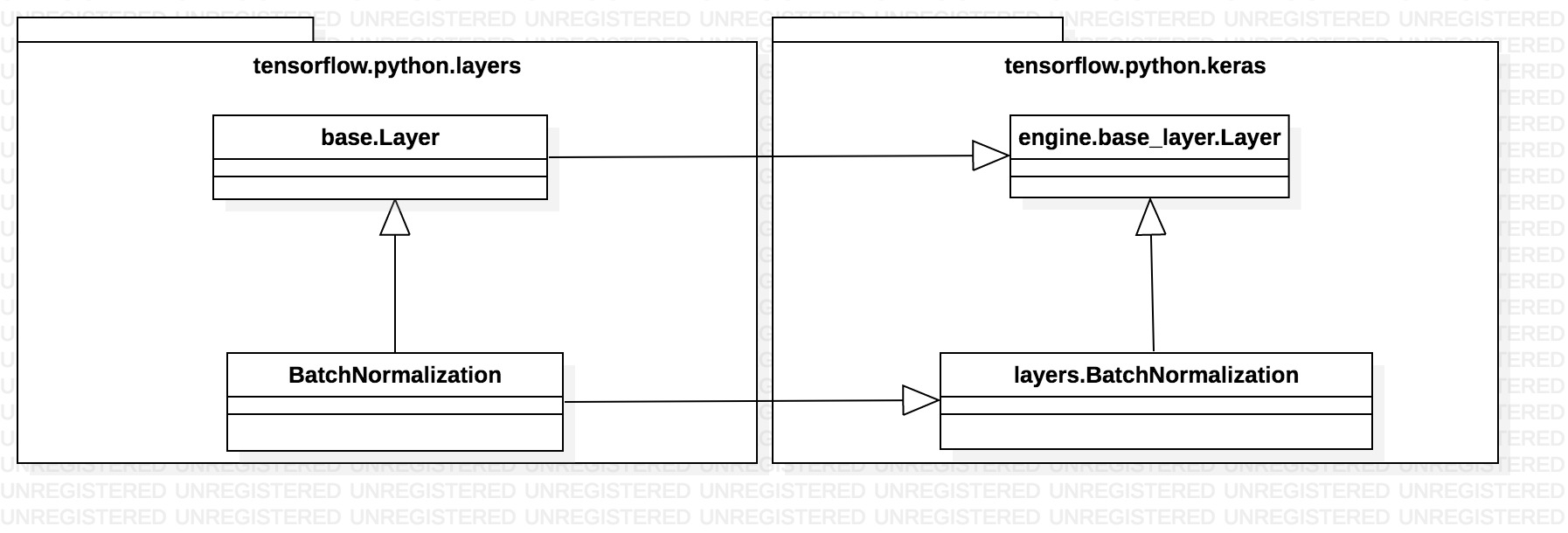
apply方法由根节点祖先类提供,实际上调用了祖先类的__call__方法。该方法会依次调用keras.layers.BatchNormalization(以下简称keras_BN类)的build方法和call方法。其中前者主要是对传入参数做一些检查以及添加变量,真正处理逻辑都在call方法中,实现的伪代码如下(这里去掉了关于批量重归一化、virtual batch、fused BN等部分的细节)
1 | from tensorflow.python.keras.utils import tf_utils |
可以参考知乎问题怎样在tensorflow中使用batch normalization?中匿名用户的回答得到一个更简洁而且实际可用的批归一化实现
进一步探索
在NIPS2018上,有两篇文章更深入地探索了批归一化成功的原因。[Bjorck2018]首先提出使用原始SGD时,每批数据引入的噪声对神经网络正则化有正向帮助,而引入噪声的两种方法是减小每批数据的大小\(|\mathcal{B}|\)或者增大学习率\(\alpha\)。实验表明,使用批归一化训练的网络(文中主要是在CV领域对CNN进行验证)可以容忍更大的学习率,因此批归一化可以增强模型的泛化能力。具体说来,使用批归一化的网络在初始化阶段梯度的大小更集中在零点附近,比较均匀;而没有批归一化的网络有严重的长尾现象。而且对于后者,学习率越大,网络越难收敛(按照文章的定义,是两次训练之间损失值差了1000倍以上),其原因是随着网络的变深,深层节点的激活值变得很大,输出“爆炸了”
另外,不使用批归一化的网络在初始化以后的训练初始阶段,倾向于将所有输入统一标记成某个类别(显然通常会给出错误的类别),因此梯度通常都是正的,加起来就是一个巨大的值,而且对不同批次数据变化不大。也就是说,网络优化的过程更多是在矫正不好的初始化状态,而不是在学习。实验还显示,对于CNN而言,即便使用了Xavier初始化方法,如果不加批归一化,某些信道也容易发生梯度爆炸的现象,一个可能原因是Xavier初始化假设初始化之后各个信道权重的方差是常量,但是这个假设太弱了。批归一化极大程度上消除了随机初始化矩阵产生病态输出,导致梯度过大的现象,因此可以使用更大的学习率训练网络,引入更多噪声,从而提高网络的泛化能力
另一篇文章[Santurkar2018]的结果更加有颠覆性,该文在分析批归一化效果显著的原因时给出了一个与原始论文截然不同的观点,即批归一化的成功与原始论文所说的“消除了内部共变量偏移”毫无关系(下文为了简便,将“内部共变量偏移”简记为ICS)。为了证明这一点,作者在批归一化层后面加入了一些随机噪声,而且噪声来源的分布均值不为0,方差也不为1,分布还会在每个时间步过后改变。尽管这种做法使得每一层的输入不再满足批归一化算法所希望的输入的性质,但是实验结果表明这样训出的模型效果与不加扰动训出的模型效果类似,收敛速度也相近,这证明ICS与训练效果并不直接相关。进一步实验表明,批归一化实际上并没有减小ICS
那么为什么批归一化能取得成功呢?文章认为,其关键在于批归一化操作重参数化了底层的优化问题,使得问题表面显著光滑了很多。对于普通的深度神经网络,损失函数不仅非凸,而且有平原有峡谷,因此使用基于梯度的算法会不稳定,对学习率和初始化敏感。而经过批归一化后,梯度变得更加可靠,有更强的预测能力,因此向着梯度方向迈出更大一步(学习率变大)以后,接下来梯度的方向仍然是比较准确的估计。意外的是,批归一化能达到的效果,使用其他\(\ell_p\)正则也可以做到,而\(\ell_1\)可能还更好一些
扩展
批归一化算法提出以后,给很多研究人员带来了启发,各种试图对某些元素归一化的方法如雨后春笋般冒出。而且批归一化算法本身对RNN和对噪声敏感的网络(例如GAN)表现也不好,因此其他方法也可以弥补批归一化的这些缺点。以下是若干比较重要的方法,不过这里不会介绍太多细节
权重归一化
权重归一化([Salimans2016a])将着眼点放在了权重上,而不是神经元的输入。对于神经元\(y = \phi({\boldsymbol{w} \cdot \boldsymbol{x}} + b)\),权重归一化将权重\(\boldsymbol{w}\)表示为 \[ \boldsymbol{w} = \frac{g}{\|\boldsymbol{v}\|}\boldsymbol{v} \] 由于\(\boldsymbol{v}/\|\boldsymbol{v}\|\)是单位向量,因此有\(\|\boldsymbol{w}\| = g\)。这样,需要被优化的参数变成了\(\boldsymbol{v}\)和\(g\)两个。根据对梯度\(\nabla_{\boldsymbol{v}}L\)的一种重写 \[ \nabla_{\boldsymbol{v}}L = \frac{g}{\|\boldsymbol{v}\|}M_{\boldsymbol{w}}\nabla_\boldsymbol{w}L,\ \ M_{\boldsymbol{w}} = \boldsymbol{I} - \frac{\boldsymbol{ww}^\mathsf{T}}{\|\boldsymbol{w}\|^2} \] 可以看出权重归一化一方面对权重的梯度做了缩放,另一方面它将梯度投射到了与当前权重向量不一样的方向,最后会导致梯度可以自稳定自己的范数(但是不能使用自适应学习率的SGD,例如Adam),因此使用权重归一化可以使网络对学习率的选择有很强的鲁棒性(训练时可以使用更大的学习率)。此外,这种分解还有助于减小梯度方向的噪声,也可以加速学习。文章指出,权重归一化可以看作是一种计算量更小、噪声更少的对批归一化方法的近似,不依赖每个小批量输入数据,因此适用于RNN、LSTM和强化学习(强化学习对噪声敏感)。最后,权重归一化实现起来要容易一些。不过根据讨论,权重归一化容易在训练时不稳定,而且对输入数据有很强的依赖性
层归一化
对固定深度的前馈网络,使用批归一化方法可以分层分别存储统计信息。但是对RNN来说,输入序列的长度通常都是变化的,因此在不同的时间步需要存储不同的统计信息。层归一化方法(layer normalization)[Ba2016]做了一定的简化,通过隐藏层输入的加和来估计归一化统计信息,因此不再依赖于具体的训练数据,更加适用于RNN。层归一化方法是一种在NLP领域里用得比较多的归一化方法,考虑到篇幅限制和方法的重要性,这部分内容将放在RNN之后介绍
组归一化
批归一化的一大问题是,每批次参与训练的数据量\(|\mathcal{B}|\) 不能太少(经验值是不要少于32)。如果\(|\mathcal{B}|\) 特别小,比如极端情况下到达2,那么误差会特别大,得到的统计量特别不准,因此训大的视觉模型时比较吃力。FAIR的何恺明组在2018年提出了一种新的归一化方法——组归一化(group normalization)[Wu2018]来解决这个问题,主要创新是将信道划分成组,计算每组的均值和方差,来做归一化。由于这种划分方式独立于\(|\mathcal{B}|\),因此对任一批次大小的数据量都可用
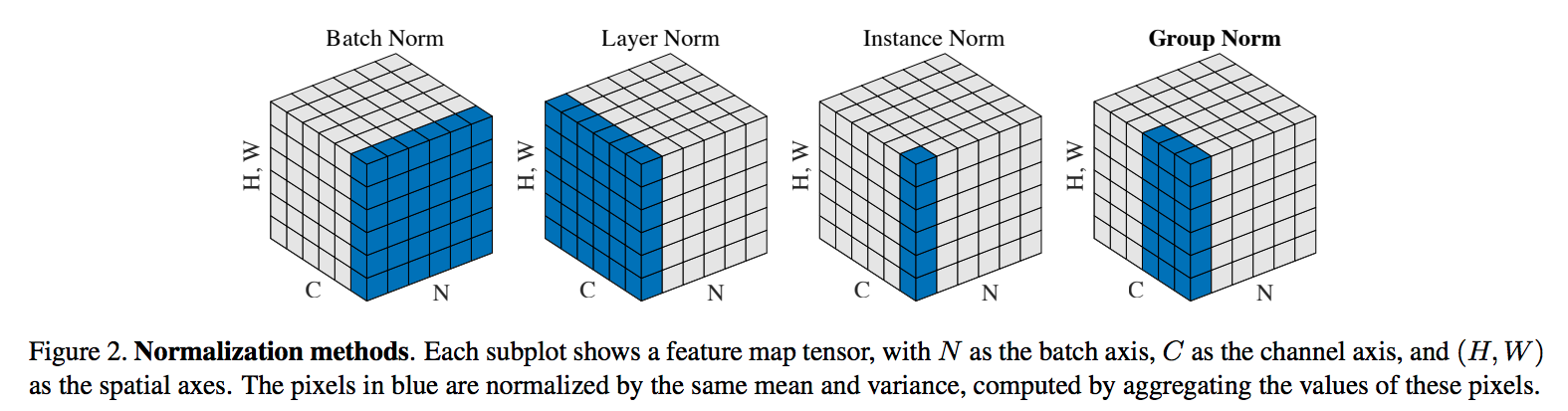
文章首先对所有归一化问题给出了一个通用的描述形式,即它们都是对输入\(x_i\)做变换 \[ \hat{x}_i = \frac{1}{\sigma_i}(x_i - \mu_i) \] 对于二维图像,\(i = (i_N, i_C, i_H, i_W)\),其中\(N\)是每小批训练数据batch轴、\(C\)是信道轴、\(H\)是空间上的高度,\(W\)是空间上的宽度。\(\mu\)和\(\sigma\)分别是均值和标准差 \[ \begin{aligned} \mu_i &= \frac{1}{m}\sum_{k\in \mathcal{S}_i}x_k \\ \sigma_i &= \sqrt{\frac{1}{m}\sum_{k \in \mathcal{S}_i}(x_k - \mu_i)^2 + \epsilon} \end{aligned} \] 归一化以后,对每个信道,要学习一个线性变换,来使得归一化后的点有缩放和移动能力,保持原始数据的表示性 \[ y_i = \gamma \hat{x}_i + \beta \] 各种归一化方法主要是在使用哪些像素点\(\mathcal{S}_i\)上有所不同:
- 批归一化方法是让同信道的所有点做归一化(即沿着\((N,H,W)\)轴做)
- 层归一化方法是让同批次的所有点做归一化(即沿着\((C,H,W)\)轴做)
- 实例归一化方法[Vedaldi2016](instance normalization,主要用于风格迁移)是让同批次各信道内的点做归一化(即沿着\((H,W)\)轴做)
- 组归一化方法是将信道划分为\(G\)个组(\(G\)是超参数,默认为32),同组信道,同批次内的点做归一化。当\(G = 1\)时,方法退化为层归一化,此时认为一层里所有信道贡献相同(不过由于卷积的存在,这个假设是不太成立的)。当\(G=C\)时,方法退化为实例归一化,但是模型无法学习信道之间的依赖关系
下图(截取自原文)给出了四种归一化方法之间的关系
组归一化方法的TF实现也比较简洁
1 | def group_norm(x, gamma, beta, g, eps=1e-5) |
组归一化背后的原理和一些视觉相关的内容有关,这里就不介绍了。有兴趣的话可以参阅原文
参考文献
花书第7章
[Sennrich2015] Sennrich, R., Haddow, B., & Birch, A. (2015). Improving neural machine translation models with monolingual data. arXiv preprint arXiv:1511.06709.
[Wang2015] Wang, W. Y., & Yang, D. (2015). That's So Annoying!!!: A Lexical and Frame-Semantic Embedding Based Data Augmentation Approach to Automatic Categorization of Annoying Behaviors using# petpeeve Tweets. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP) (pp. 2557-2563).
[Zhang2015] Zhang, X., & LeCun, Y. (2015). Text understanding from scratch. arXiv preprint arXiv:1502.01710.
[Junczys-Dowmunt2016] Junczys-Dowmunt, M., Dwojak, T., & Sennrich, R. (2016). The AMU-UEDIN submission to the WMT16 news translation task: Attention-based NMT models as feature functions in phrase-based SMT. arXiv preprint arXiv:1605.04809.
[Izmailov2018] Izmailov, P., Podoprikhin, D., Garipov, T., Vetrov, D., & Wilson, A. G. (2018). Averaging Weights Leads to Wider Optima and Better Generalization. arXiv preprint arXiv:1803.05407.
[Srivastava2014] Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. (2014). Dropout: a simple way to prevent neural networks from overfitting. The Journal of Machine Learning Research, 15(1), 1929-1958.
[Hara2016] Hara, K., Saitoh, D., & Shouno, H. (2016, September). Analysis of dropout learning regarded as ensemble learning. In International Conference on Artificial Neural Networks. Springer, Cham. (pp. 72-79)
[Ioffe2015] Ioffe, S., & Szegedy, C. (2015). Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167.
[Bjorck2018] Bjorck, J., Gomes, C., & Selman, B. (2018). Understanding Batch Normalization. In Proceedings of Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018 (NeurIPS) (pp. 7705-7716).
[Santurkar2018] Santurkar, S., Tsipras, D., Ilyas, A., & Madry, A. (2018). How Does Batch Normalization Help Optimization?. In Proceedings of Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018 (NeurIPS) (pp. 2488-2498).
What is right batch normalization function in TensorFlow
[Salimans2016a] Salimans, T., & Kingma, D. P. (2016). Weight normalization: A simple reparameterization to accelerate training of deep neural networks. In Advances in Neural Information Processing Systems 2016 (NeurIPS) (pp. 901-909).
[Ba2016] Ba, J. L., Kiros, J. R., & Hinton, G. E. (2016). Layer normalization. arXiv preprint arXiv:1607.06450.
Pros and cons of weight normalization vs batch normalization
tf.layers.batch_normalization large test error
[Wu2018] Wu, Y., & He, K. (2018). Group normalization. arXiv preprint arXiv:1803.08494.
[Vedaldi2016] Vedaldi, V. L. D. U. A. (2016). Instance Normalization: The Missing Ingredient for Fast Stylization. arXiv preprint arXiv:1607.08022.
[Salimans2016b] Salimans, T., Goodfellow, I., Zaremba, W., Cheung, V., Radford, A., & Chen, X. (2016). Improved techniques for training gans. In Advances in Neural Information Processing Systems (NeurIPS) (pp. 2234-2242).
[Ioffe2017] Ioffe, S. (2017). Batch renormalization: Towards reducing minibatch dependence in batch-normalized models. In Advances in Neural Information Processing Systems (NeurIPS) (pp. 1945-1953).
