从最抽象的角度来讲,机器学习问题的求解过程就是提出一个损失函数来度量模型预测值与真实值之间的差距,然后通过某种给定的优化方法来调整模型参数,使模型效果提升的过程。在这个过程中,选择正确的损失函数是问题求解的基础,而对于某些特定的问题,设计一个有针对性的,新的损失函数则可以看作是胜负手
常见的损失函数通常都适用于有监督学习问题,其中根据问题的不同类型,损失函数也可以划分为两类:针对回归问题的损失函数和针对分类问题的损失函数。在本节后面的阐述中,除非特别说明,记\(\boldsymbol{y}\)为真实值,\(\hat{\boldsymbol{y}}\)为预测值,\(N\)为样本个数
针对回归问题的损失函数
均方误差函数
求解回归问题时,最常见的损失函数无疑是均方误差函数(均方误差:mean squared error, MSE),也称为\(\ell_2\)误差函数。具体形式为 \[ {\rm MSE}(\boldsymbol{y}, \hat{\boldsymbol{y}}) = \frac{1}{N}\sum_{i=1}^N\left(y_i - \hat{y}_i\right)^2 \] 由上式可知,如果使用均方误差函数做损失函数,模型做出的预测与实际值差得越多,则受到的惩罚越大。因此,如果数据集中有离群点,则会很大程度上影响最终学到的模型。但是,从另一方面讲,如果不希望模型的预测值与某个真实值相差太远,均方误差函数则是一个很好的选择
平均绝对值误差函数
均方误差函数如果写成向量形式,则为 \[ {\rm MSE}(\boldsymbol{y}, \hat{\boldsymbol{y}}) = \frac{1}{N}\left|\!\left|\boldsymbol{y}-\hat{\boldsymbol{y}}\right|\!\right|^2_2 \]
也就是说,均方误差函数的核心是预测值与真实值这两个向量差的\(\ell_2\)范数。考虑到正则化里有\(\ell_2\)正则化和\(\ell_1\)正则化,那么对于损失函数,求预测值与真实值这两个向量差的\(\ell_1\)范数是不是一个好的选择?的确如此,这种损失函数更多被称为平均绝对值误差函数(平均绝对值误差:mean absolute error, MAE)。具体形式为 \[ {\rm MAE}(\boldsymbol{y}, \hat{\boldsymbol{y}}) = \frac{1}{N}\sum_{i=1}^N\left|y_i - \hat{y}_i\right| \] MAE的最大问题是损失函数在\(y_i = \hat{y}_i\)处不可导,因此在计算梯度时可能会造成问题
对于这两个比较常见的损失函数,一个自然而然的问题就是,实际问题中究竟应该选择哪个?对于这个自然而然的问题,有一个自然而然的答案,就是具体问题具体分析。然而,有一些基本的事实是不能忽视的。首先,MSE处处可导,易于优化。其次,需要考虑:如果对于两个样本,模型给出的预测值与第一个样本差了\(\delta\),与第二个样本差了\(2\delta\),那么模型在第二个样本上的表现的拙劣程度,是不是在第一个样本上表现的拙劣程度的两倍?更广泛地说,模型预测值与真实值的差距,是否与人们对这个模型的失望程度呈线性关系?如果的确是线性关系,那么MAE可以使用;如果模型预测值的离谱程度会放大人们的失望程度,那么还是应该使用MSE(事实上,MSE也的确使用更广,而离群点的问题可以通过其它手段来克服)。此外还需注意的一点是,MSE对参数的梯度会随着损失值的减小而变小,因此即使学习率不变也容易收敛;而MAE对参数的梯度不随损失值的变化而变化,是一个常量,因此需要即时调整学习率
根据维基百科,MSE可以看作是误差的算术平均值无偏估计,而MAE则是误差的中位数无偏估计。关于这两种损失函数比较的进一步阅读,可以参考 Chai, Tianfeng, and Roland R. Draxler. "Root mean square error (RMSE) or mean absolute error (MAE)?–Arguments against avoiding RMSE in the literature." Geoscientific model development 7.3 (2014): 1247-1250.
Huber loss
针对MSE对离群点鲁棒性不太强的弱点,Huber提出了一种新的损失函数来进行弥补,称为huber loss。其定义为 \[ {\rm huber}(y_i, \hat{y}_i) = \begin{cases}\frac{1}{2}(y_i - \hat{y}_i)^2 & {\rm if\ }|y_i - \hat{y}_i| \le \delta \\ \delta|y_i - \hat{y}_i| - \frac{1}{2}\delta^2 & {\rm elsewhere}\end{cases} \] 其核心思想是,假设预测值和真实值之间差值的绝对值在给定的参数\(\delta\)内,则认为原始数据点是正常点,使用平方误差来求损失值;否则认为原始数据点可能是离群点,使用绝对值误差并减去一个与\(\delta\)有关的量来求损失值。在sklearn关于huber回归的文档中,建议将\(\delta\)设置为1.35以达到95%的统计有效性

上图来自维基百科,给出了\(\delta=1\)时的huber loss与平方误差之间的关系。原图中并没有标记坐标轴的意义,参考ESL一书可知横轴为预测值与真实值之间的差,而纵轴为损失函数值。可以看出随着预测值与真实值之间差距的拉大,huber损失函数值只是呈线性缓慢增长,与绝对值误差函数相似
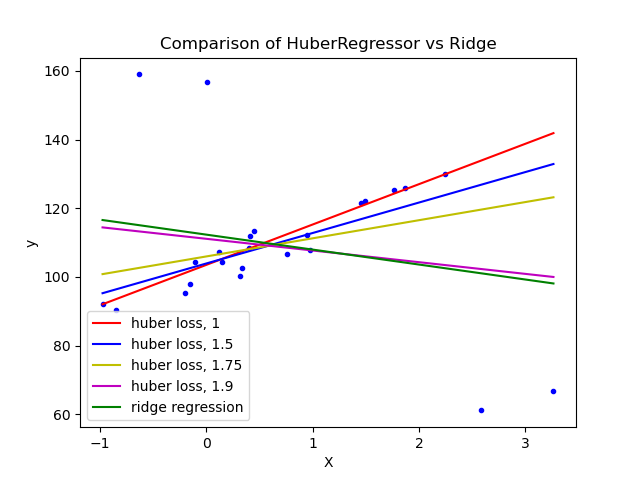
上图来自于sklearn官方文档,给出了在有若干明显离群点的数据集上分别使用huber回归(各模型使用的\(\delta\)不同)和岭回归的对比图。可以看出在设置了合适的\(\delta\)时huber回归的效果要明显好很多
关于回归问题的损失函数小结
上述三种损失函数的关系大致如下图所示
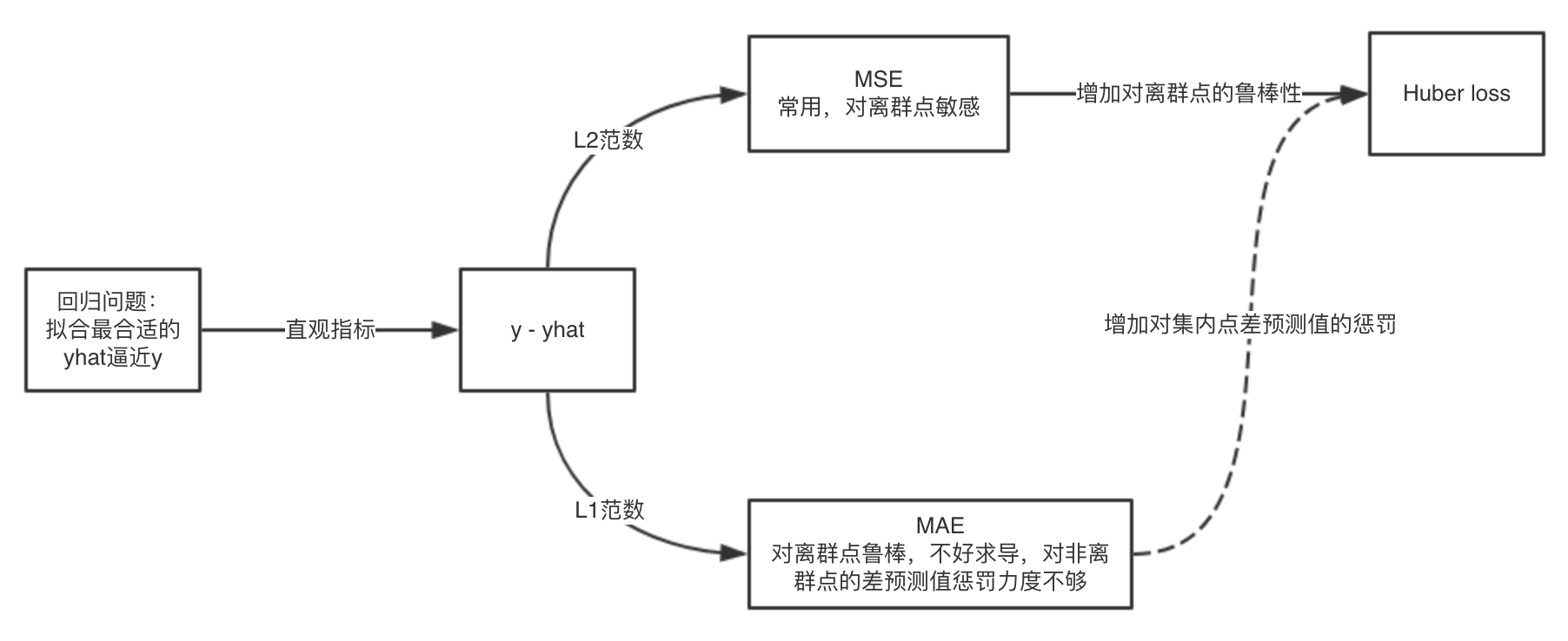
其与TensorFlow提供的损失函数有如下对应关系
- MAE,对应于
tf.losses.absolute_difference - MSE,对应于
tf.losses.mean_squared_error - huber loss,对应于
tf.losses.huber_loss
TensorFlow还提供了tf.losses.mean_pairwise_squared_error来逐对计算平方误差。这种损失函数比较繁琐而且用得不多,这里就不介绍了(另外,根据stackoverflow的一个回答,在TF1.6之前的版本里这个损失函数的实现甚至是有bug的)
针对分类问题的损失函数
交叉熵损失函数
概述
对于分类问题,最常使用的损失函数是交叉熵损失函数(cross entropy loss function)。接下来的讲述来自于花书的5.5节(不过对逻辑做了一些修改)
对于给定的若干样本,假设它们的标签符合某种真实的分布\(p_{\rm data}({\bf x})\)(对于最常见的二分类问题,这个分布是某个伯努利分布),但是这个真实分布无从得知,能够观察到的也仅是训练集上的经验分布\(\hat{p}_{\rm data}\)。设计模型的目标就是要使得由模型参数\(\boldsymbol{\theta}\)确定的分布\(p_{\rm model}(\boldsymbol{\theta},{\bf x})\)能够逼近真实分布,即对任意的\(\boldsymbol{x}\)使\(p_{\rm model}(\boldsymbol{\theta},\boldsymbol{x})\)逼近于\(p_{\rm data}(\boldsymbol{x})\)。在解决两个概率分布近似程度度量的问题时,通常使用KL散度,即 \[ D_{\rm KL}(\hat{p}_{\rm data} \| p_{\rm model}) = \mathbb{E}_{ {\bf x}\sim \hat{p}_{\rm data}}\left[\log \hat{p}_{\rm data}(\boldsymbol{x}) - \log p_{\rm model}(\boldsymbol{x})\right] \] 这个值越小,说明两个分布越接近。因此,模型的目标就是最小化上面的\(D_{\rm KL}\)。去掉与模型无关的项,最小化KL散度等价于最小化 \[ -\mathbb{E}_{ {\bf x}\sim \hat{p}_{\rm data}}\left[ \log p_{\rm model}(\boldsymbol{x})\right] \] 也就是真实分布与模型预测分布之间的交叉熵(从信息论的角度讲,交叉熵的意义也可以理解为,使用预测分布表示真实分布所需的平均编码长度)。当两个概率分布都是离散分布时,上式等价于 \[ -\frac{1}{m}\sum_{i=1}^m \hat{p}_{\rm data}(\boldsymbol{x}_i)\log p_{\rm model}(\boldsymbol{x}_i) \] 如果记\({\bf y}_i\)为第\(i\)个样本的真实的标签向量(当分类问题时多分类问题时,真实的标签向量通常是一个独热编码向量。例如对某个5-分类问题,如果样本的真实标签是3,那么对应的向量是[0, 0, 0, 1, 0]),\(\hat{\bf y}_i\)为模型给出样本属于各真实标签的概率组成的向量,那么最小化上式又等价于最小化 \[ -\frac{1}{m}\sum_{i=1}^m{\bf y}_i\cdot \log{\hat{\bf y}}_i \] 最小化交叉熵损失函数也等价于使用最大似然法求解最优的\(\boldsymbol{\theta}_{\rm ML}\),因为 \[ \begin{align*} \boldsymbol{\theta}_{\rm ML} &= \mathop{ {\rm arg}\max}_{\boldsymbol{\theta}}p_{\rm model}\left(\mathbb{X};\boldsymbol{\theta}\right) \\ &= \mathop{ {\rm arg}\max}_{\boldsymbol{\theta}} \prod_{i=1}^m p_{\rm model}(\boldsymbol{x}^{(i)};\boldsymbol{\theta}) \\ &= \mathop{ {\rm arg}\max}_{\boldsymbol{\theta}} \sum_{i=1}^m \log p_{\rm model}(\boldsymbol{x}^{(i)};\boldsymbol{\theta}) \\ &= \mathop{ {\rm arg}\max}_{\boldsymbol{\theta}} \frac{1}{m}\sum_{i=1}^m \log p_{\rm model}(\boldsymbol{x}^{(i)};\boldsymbol{\theta}) \\ &= \mathop{ {\rm arg}\max}_{\boldsymbol{\theta}} \mathbb{E}_{ {\bf x}\sim \hat{p}_{\rm data}}\log p_{\rm model}(\boldsymbol{x};\boldsymbol{\theta}) \\ &= \mathop{ {\rm arg}\min}_{\boldsymbol{\theta}} -\mathbb{E}_{ {\bf x}\sim \hat{p}_{\rm data}}\log p_{\rm model}(\boldsymbol{x};\boldsymbol{\theta}) \end{align*} \]
Softmax交叉熵损失函数
对多元分类问题,一般情况下我们认为对任意给定的数据,其只应该被标记为一个确定的且唯一的标签。对于这样的问题,通常的方法是计算样本对各类别的得分,然后对得分做一个softmax归一化,这样得到的结果可以解释为样本被模型判断属于各类别的概率。对于这种问题,在TensorFlow中,使用tf.losses.softmax_cross_entropy来计算预测值与真实值之间的交叉熵。但是需要注意的是,TensorFlow中用来计算交叉熵的预测值是原始得分。该损失函数,如函数名称所示,会对原始得分做一个softmax,将softmax得分分别求负对数,然后将负对数的结果与真实值做内积。由于真实值通常是一个独热编码,因此实际上等价于找出负对数向量中的第\(i\)个分量,这里\(i\)是样本所属的真实标签序号。例如
1 | import tensorflow as tf |
在上述示例中,两条数据都可能属于4个类别0、1、2、3中的一个,真实数据标签分别为3和2。假设模型对两条数据给出分属各个类别的得分都是[1, 2, 3, 4],那么得分被softmax归一化以后为[0.0320586 , 0.08714432, 0.23688282, 0.64391426]可以看作是模型对数据属于各类别的概率做出的预测。将该数组中各元素取负对数得到[3.4401897, 2.4401897, 1.4401897, 0.4401897]。第一条数据预测值与真实值的交叉熵为0.44,第二条数据为1.44,两者相加再求平均即可得到0.94
使用tf.losses.softmax_cross_entropy时,要求每条数据传入的真实标签是一个独热编码后的向量。如果希望只传入类别的id,那么可以使用tf.losses.sparse_softmax_cross_entropy。接续上面的代码片段
1 | sparse_softmax_celoss = tf.losses.sparse_softmax_cross_entropy(y_true, y_pred) |
可以看到两者相同
Sigmoid交叉熵损失函数
前面提到,softmax交叉熵损失函数隐含认为每个样本所属的类别是唯一的。但是在某些情况下,并不要求给定样本的类别标签两两互斥,在这种情况下,softmax交叉熵损失函数就不是一个好的选择(这也再次说明,需要具体问题具体分析,针对问题挑选合适的损失函数!)。作为替代品,TensorFlow提供了tf.losses.sigmoid_cross_entropy损失函数来解决这个问题,此时模型给出的得分不再统一做归一化,而是对每个分量分别施加sigmoid函数。这样,分数的每个分量仍然可以被解释为模型认为该样本属于对应类别的概率,但此时分量之间是独立的。举个例子,假设对于一个二分类问题,对于某条数据,模型给出的原始分数是[100, 100],那么使用softmax交叉熵函数隐含认为该数据属于两个类的概率各为50%,而使用sigmoid交叉熵函数认为该模型属于两个类的概率都接近100%。使用前面给出的示例数据
1 | import tensorflow as tf |
sigmoid交叉熵函数的计算略微复杂一点,这里以上面代码例子中第一条数据为例。
- 首先,将所有得分分别求sigmoid,这样[1, 2, 3, 4]被转化成[0.73105858, 0.88079708, 0.95257413, 0.98201379]
- 然后,用1减去上面得到的sigmoid得分,同时也用1减去真实标签,得到[0.26894142, 0.11920292, 0.04742587, 0.01798621]和[1, 1, 1, 0]
- 对两个与sigmoid有关的向量分别求负对数,得[0.31326169, 0.12692801, 0.04858735, 0.01814993]和[1.31326169, 2.12692801, 3.04858735, 4.01814993]
- 将负对数向量与各自的标签向量分别求交叉熵,得到0.01814993和1.31326169 + 2.12692801 + 3.04858735 = 6.48877705
- 两者求和并除以类别数:(6.48877705 + 0.01814993) / 4 = 1.626731745
通过同样的方法可以得到第二条样本的sigmoid交叉熵为1.876731745。因此样本的总体交叉熵为两条样本交叉熵的均值,为1.751731745
(与代码框中直接计算的结果有些许不同,但是感觉可以忽略)
记样本个数为\(m\),类别数量为\(k\),上述过程可以形式化地写为 \[ \begin{align*} {\rm sigmoid\_CE} &= \frac{1}{m}\frac{1}{k}\sum_{i=1}^m\left( -{\bf y}_i\log \hat{\bf y}_i - ({\bf 1} - {\bf y}_i)\log({\bf 1}-\hat{\bf y}_i) \right) \\ \hat{\bf y}_i &= \sigma({\rm score}_i) \\ \sigma(x) &= \frac{1}{1+e^{-x}} \end{align*} \] 从上面两个例子中可以观察到一个现象:对于上述例子中给定的数据和真实标签,使用sigmoid交叉熵函数得到的损失值比使用softmax交叉熵函数得到的损失值要大一些。究其原因是,模型对四个类别给出的原始得分都是正数,经过sigmoid变换以后,考虑sigmoid交叉熵函数要解决的问题,损失函数会以为模型觉得原始样本属于第1、2、3个类别的概率都很大。但是核对真实标签,发现数据只应属于第2/3个类别,因此损失函数会认为模型做出了错误的判断。通过这个例子,可以更清楚地看到正确选择损失函数的重要性
上面的形式化表示与Logistic回归的损失函数形式上非常像,的确如此,如果将类别个数限定为2,sigmoid交叉熵函数与Logistic回归的损失函数是相同的。事实上,如果要传给损失函数的是已经被sigmoid的值,那么将该预测值和真实值送入TensorFlow提供的tf.losses.log_loss函数,与将原始分数和真实值送入tf.losses.sigmoid_cross_entropy函数得到的结果是相等的
铰链损失函数(hinge loss)
Hinge loss是一种与交叉熵损失函数思路不同的损失函数,它没有使用负对数做最大似然估计,衡量的也不是两个分布之间的差别。对某条数据,假设模型给出的预测值\(\hat{y} \in \mathbb{R}\),真实值\(y \in \{-1, 1\}\),则hinge loss的形式为 \[ {\rm HingeLoss}(y, \hat{y}) = \max(0, 1-y\cdot \hat{y}) \] 这里\(\hat{y}\)不是最后的标签,而是模型输出的原始得分。对该损失函数,可以将输入分为三种情况来考虑
- 真实标签与预测值同号,且预测值分数(的绝对值)很高:此时\(y \cdot \hat{y}\)是一个远大于1的数,因此\(1-y\cdot \hat{y} < 0\),样本对损失函数没有贡献
- 真实标签与预测值同号,但预测值分数(的绝对值)比较小:此时\(0 < y \cdot \hat{y} < 1\),样本对损失函数有贡献,但是不大,\(0 < \ell < 1\)
- 真实标签与预测值异号,此时损失函数值必然大于1。即模型会对这样的数据施加很大的惩罚,而且预测值绝对值越大,说明错得越离谱,惩罚也越大
综上所述,使用hinge loss会主要根据错分样本调整模型参数,次要地根据正确分类但是信心不强的样本调整参数,但是正确分类且信心很强的样本对模型没有影响。这样得到的(线性)模型可以达到最大间隔分离超平面的效果——这种模型也正是传统统计学习中很受重视的支持向量机SVM。事实上,对如下常见的SVM问题的形式化描述 \[ \begin{align*} \min_{b, {\bf w}}\hspace{2ex}&\frac{1}{2}\left\|{\bf w}\right\|_2^2 + C\cdot \sum_{n=1}^N \xi_n\\ {\rm s.t.} \hspace{2ex} &y_n({\bf w^\mathsf{T}z}_n + b) \ge 1 -\xi_n,\ \xi_n \ge 0 \forall n \end{align*} \] 记\({\bf w^\mathsf{T}z}_n + b\)为\(\hat{y}_n\),则对限制条件,有 \[ y_n \cdot \hat{y}_n \ge 1 - \xi_n \Rightarrow \xi_n \ge 1-y_n\cdot \hat{y}_n \] 又\(\xi_n \ge 0\),因此优化条件可以写为 \[ \begin{align*} \min_{b, {\bf w}} \frac{1}{2}\left\|{\bf w}\right\|^2_2 + C\cdot \sum_{n=1}^N {\rm HingeLoss}(y_n, \hat{y}_n) \end{align*} \] 这意味着SVM可以看作是对hinge loss的优化再加一个\(\ell_2\)正则项
Hinge loss的好处是在没有离群点的情况下其对未知数据分类的准确度比较高,因为直观地讲,使用hingle loss训练得到的分类器的目标是尽可能把两类数据分得很开,这样就降低了新数据落在分类器另一边的可能(图例可见之前林轩田老师课程笔记)。但是,hinge loss也会比较严重地受到离群点的影响
以SVM为代表的使用hinge loss为损失函数的模型还有一个比较重要的短板,就是它不能提供一个很好的概率解释(这也是使用sklearn的SGDClassifier做分类器时的一个大坑。因为这个分类器默认的损失函数就是hinge loss,这样得到的模型调用概率预测函数predict_proba时会报错,所以要让该分类器给出概率估计,必须在构造分类器时手动传'log'作为loss这一参数的值)。从原理上讲,MLE和减小KL散度的目的都是经验风险最小化,而hinge loss的目的是结构风险最小化
此外,hinge loss这一函数在\(y\cdot \hat{y} = 1\)时不可导,因此使用基于梯度的优化方法时需要一些额外工作。但是,SVM问题本身是一个凸优化问题,所以求解该问题时通常直接使用二次规划的方法解决
均方误差函数
将MSE纳入本章纯粹是为了顾及内容的完备性。从理论上讲,用MSE来解决分类问题也是可行的,因为MSE也是真实0-1误差的上界(可以参考林轩田老师课程笔记)。但是真正使用MSE来做分类问题的损失函数是有问题的。理论上讲,MSE假设误差遵循高斯分布,而分类问题的误差一般都是二项分布,两者分布不同。从实际上讲,前面提到过,MSE倾向于惩罚离群点,而对于分类问题中的数据,在MSE看来的“离群点”反而可能是那些离真实边界最远的点。如果使用MSE训练分类器,训练出的分界线会向这些“离群点”靠近,因此反而会错分那些离真实边界比较近的点。参考下图(来自于PRML)

因此,分类问题一般不使用针对回归问题的损失函数
关于分类问题的损失函数小结
上述各损失函数的关系大致如下图所示(这里没有包括均方误差函数)
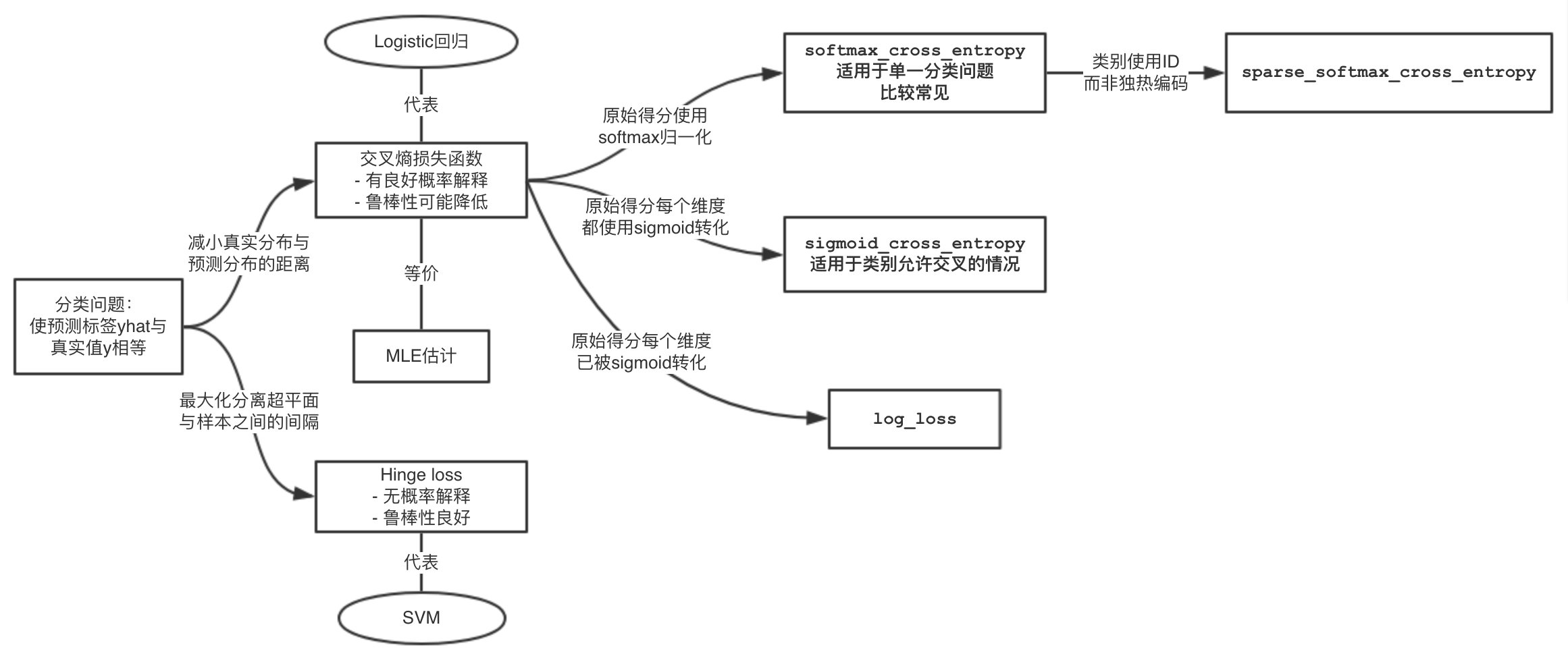
神经翻译领域,大部分情况下都是使用softmax_cross_entropy作为损失函数
