从主成分分析到自动编码器
主成分分析(PCA)的思想是,高维数据通常可以使用很低维度的数据编码。假设输入是\(N\)维数据,现在想用\(M\ (M<N)\)维的数据表示之,方法是选择\(M\)个相互正交的方向,且数据在这些方向上有最大的方差,然后略去剩下\(N-M\)个数据不大的方向。这样,\(M\)个主方向就形成了一个低维子空间,可以将原始\(N\)维数据表示成它在子空间上的投影。由于舍弃的信息在舍弃的方向上变化不大,所以没有什么损失。要从降维表示的数据重构原有数据,只需要在舍弃的方向上使用所有数据在该方向上的均值,误差就是数据点在未表示方向上的分量与均值的差的平方和,如下图所示
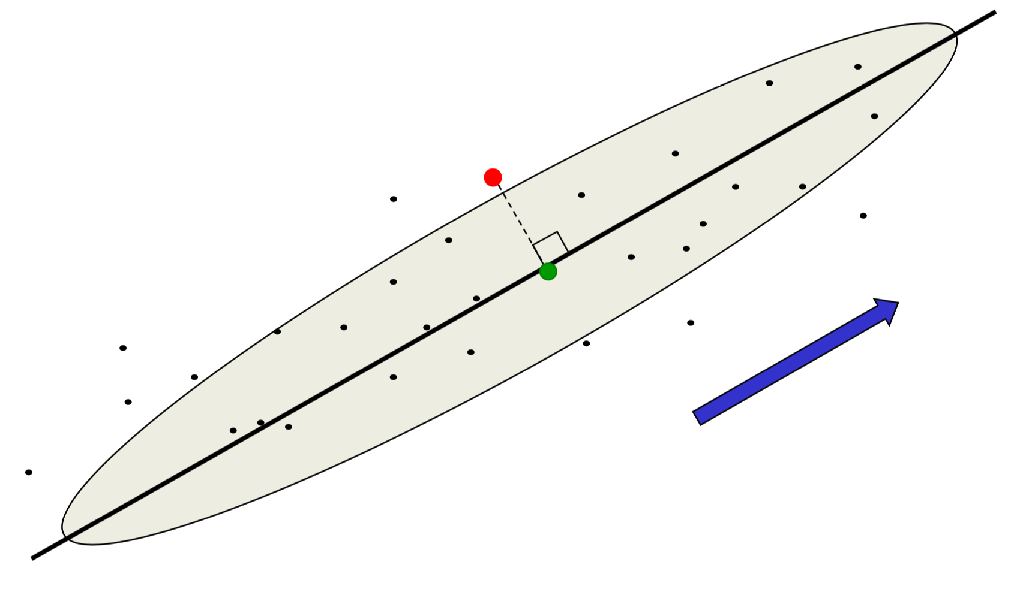
PCA将二维空间中的数据投影到黑色粗线上,其中红色的点投影后会变成绿色的点。重构误差是红点和绿点之间距离的平方
可以使用反向传播实现PCA,但是效率不高。网络结构是,输入和输出都是\(N\)维的,中间隐藏层有\(M\)个神经元,然后要减少输出和输入之间的平方误差。此时,中间的\(M\)维向量就是降维后的压缩表示。如果隐藏神经元和输出神经元都是线性的,学到的隐藏单元就可以最小化重构误差,就像PCA做的那样。不过隐藏单元不一定是主成分,它们跟主成分在一个线性空间中,但是可能有一些翻转和倾斜,方向不正交,而且M个分量倾向于有相等的方差
使用反向传播实现PCA尽管效率不太高,但是可以对算法进一步泛化。假设在降维表示的前面和后面加入两层非线性,靠近输入的称为编码权重,靠近输出的称为解码权重,那么就可以把数据表示到一个弯曲的面上,而非平面。这种做法像是在用监督学习方法来做无监督学习,得到的模型称为自动编码器
深度自动编码器
深度自动编码器,顾名思义,就是层数更多的自动编码器。它看上去应该比PCA更擅长做维度缩减,因为在两个方向上(输入到低维表示和低维表示到输出)都提供了灵活的映射,而且这种映射可以是非线性的。深度自动编码器的训练时间应该是线性于输入数据集大小的,而且训练好以后,网络的编码部分应该很快,因为实质上就是矩阵相乘。但是不幸的是,很难使用反向传播来优化自动编码器,因为通常人们都使用很小的初始权重,因此反向传播时梯度会很快消失。不过现在,可以使用无监督的与训练方法逐层生成初始权重,或者像回声状态网络那样合理对权重初始化。2006年,Russ Salakhutdinov和Hinton实现了第一个成功的深度自编码器,他们训练了4个RBM,堆叠起来然后展开,最后使用反向传播做微调,效果很好
用于文档检索的深度自动编码器
文档检索的核心是计算两篇文档之间的相似度。一种比较传统的方法是潜在语义分析(Latent Semantic Analysis, LSA),它的做法是从文档中提取每个单词的数量,然后对得到的向量组成的矩阵做PCA。具体说,首先把文档转换成一个大的词袋,即维护一个很大的数组(向量),单词都转换为ID,数组中单词ID对应的下标是这个单词出现的数量。这种做法会丢失词之间的顺序信息,不过仍然保留了最基本的信息(此外,还要去掉一些跟主题无关的“停用词”,例如the, a, an这种)。假设词表大小为2000,有上百万个文档,那么就会得到上百万个2000维的向量。对于给定的文档,如果逐一比对,计算肯定慢死了。为了提高速度,需要对这个大矩阵降维,例如降到10维。以前的思路是使用PCA,但是既然深度自动编码器的效果比PCA要好一些,就可以使用深度自动编码器来做这个事情。网络分为7层,输入层和输出层(第1和第7层)都是2000维,第2层使用500个神经元(第6层同),第3层使用250个神经元(第5层同),最后第4层成为一个“瓶颈”,只有10个神经元,网络的目的就是要把原始2000维的信息放到这10个神经元里
需要注意的是,词数和像素值还不太一样,所以要把词袋中每个单词的个数除以停用词总个数\(N\),这样每个向量都可以看作是一个概率向量,即该向量在所有维度上的值相加为1。可以这么理解,就是每个词对应的值是随便在文档里取一个非停用词,然后取到了这个值的概率。自动编码器的输出层是一个2000维softmax,输出的值也可以看作是一种概率向量。此外,这里还使用了一个技巧:使用输入向量激活第一个隐藏层时,将所有权重乘以\(N\),来放大这个RBM中自底向上的权重
(后面效果略)
语义哈希
前面提到,可以训练一个深度自动编码器来产生文档的压缩表示,最中间一层的结果就是文档在低维空间的映射(前一节是10维,这一节是30维)。在训练时,先训练若干个RBM,把它们堆叠起来,然后展开,使用编码器权重的转置做相应解码器的权重,然后使用反向传播做微调。微调时,在输入端加入一些高斯噪声,因此自动编码器需要把神经元更倾向于调到恒开或恒关,以抵抗噪声的干扰。在测试的时候,直接把中间编码层神经元的值按照阈值设为0或1,这样,自动编码器会把词袋模型转化成少数几个二进制数,也就是说,学到一些二进制特征
后来,Alex Krizhevsky(似乎就是AlexNet的发明人?)发现其实不需要加入高斯噪声,只需要使用随机二进制单元就可以。这样,在正向阶段,使用logistic的结果随机输出一个0/1值,然后,在反向阶段使用logistic的实数输出来得到光滑的梯度
得到这些短的二进制码后,就可以对每个已知的文档做一个顺序搜索。当查询文档到来时,首先提取这个二进制码,如果这个码不对应于任何已知文档,就和所有已知文档的编码作比较。尽管这种比较操作可以通过位运算很快完成,但是当已知文档数以亿计时,还是有点慢。因此,可以把这些编码看作是内存地址,当查询到来时,直接看查询文档的地址周围有哪些编码好的文档(可以通过翻转较少几位的方法来达到查看周边地址的功能),这些文档就是相似文档。这种方法被Hinton称为“超市搜索法”,就好像你进到一个没去过的超市,想买鯷鱼罐头但不知道怎么走,就可以问导购金枪鱼罐头哪里卖,然后去ta指的地方附近找鯷鱼罐头
还可以从另一个角度理解语义哈希。大部分快速的检索算法都是先从查询中提取一些关键字,然后找到对应的索引列表。例如Google会维护一个含有罕见词文档的倒排索引,当查询中有对应的罕见词时,马上就可以找到文档列表,然后将这个列表与其他列表做集合相交的操作来找到满足所有查询的文档。现在,计算机有一种特殊的硬件,称为内存总线(memory bus),它可以在单条指令里对32个特别长的列表求交集,32位编码中每个bit都对应内存中一半的地址。语义哈希实际上就是用机器学习技术来将检索问题映射到计算机擅长做的列表相交问题
为图像检索学习二进制编码
传统的图像检索通常都是利用图像的题注来做,但是为什么不直接使用图像呢?图像包含的信息肯定要比题注多。这里最基本的问题是图像的单个像素对说明图像内容没有太多贡献,而从图像中提取出来物体类别太难了(本条已过时)。退而求其次,那是否可以从图像中抽取出来一个向量,而让这个向量包含图像内容的信息呢?如果对向量的大小不加限制,那么查找效率和存储都是问题,所以需要像语义哈希那样学习一个简短的二进制编码
这里具体使用的是一个两阶段方法。首先,使用一个短小的二进制编码(大概30位),来通过语义哈希快速缩小查找范围,将目光聚焦到若干靠谱的图像上。然后,使用一个稍长的二进制编码(256位)做一个精确匹配。Alex Krizhevsky设计的网络结构如下所示
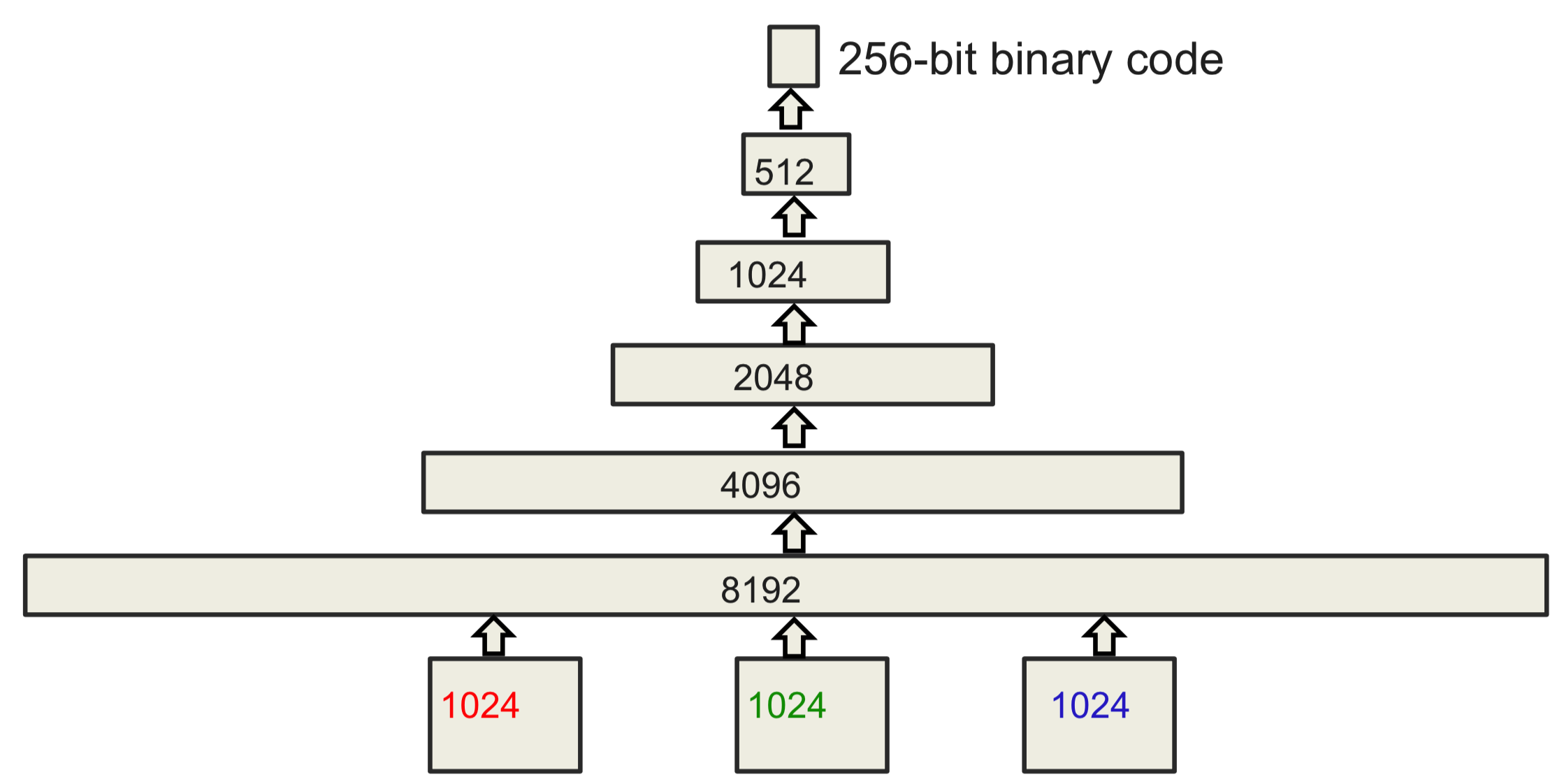
其中输入是32x32的图像,分成RGB三个信道,所以输入共有3072维。整个网络有6700万个参数
(中间效果介绍略)
进一步地,我们希望信息提取能对图像的内容更敏感,而不是对像素密度敏感。要达到这样的效果,可以先训练一个巨大的,用来做物体识别的网络(如第五章所讲的网络),然后去这个网络最后一个隐藏层的激活向量,将其看作是图像的表示
(效果介绍略)
用于预训练的浅层自动编码器
说完了深层自动编码器,这里想说一下只有一个隐藏层的浅层自动编码器。当训练RBM时,如果使用的是一个时间步的对比散度训练,那么它会试着重新构造出与训练数据比较像的数据。这种模型看上去像是一个自动编码器,但是由于隐藏单元只允许取0或1的值,因此它其实被正则化得比较狠,因此能力收到了很大限制。如果使用最大似然法训练RBM,那么得到的模型就完全不像自动编码器了:假设某个像素点是个纯噪声,自动编码器会试图重构它,而使用最大似然训练的RBM会完全忽视这个像素,只使用输入的偏置建模
由于RBM可以看做是一种经过了强正则化得到的自动编码器,也许可以把预训练时用到的RBM替换为自动编码器的堆叠。如果直接这么做的话,预训练的效果不是特别好。但是,如果稍作改进,情况会不太一样。Vincent等人提出了一种降噪自动编码器的模型,训练这种模型时,要将输入向量的大部分维度都设为0(不同的输入被置0的维度不同)。这种做法像是在输入层做dropout。由于降噪自动编码器的目标仍然是重构数据,而且输入缺少了很多信息,因此它就会被逼着使用隐藏节点提取输入之间的关联性,重构出被置零的数据。如果将降噪自动编码器堆叠起来,效果会不错,可以跟堆叠RBM相提并论,甚至更好。这种方法唯一的问题是缺少RBM那样优美的差分下界,不过这是理论界要解决的问题
2011年,Rifai等人提出了一种称为收缩自动编码器(contractive autoencoder, CAE)的模型。核心思想史让隐藏单元的激活尽可能不敏感于输入(不过不能完全忽略输入,毕竟是要重构它们)。达到这个目标的做法是对每个异常单元对每个输入的梯度的平方做惩罚,因此当输入变化的时候,隐藏单元不会发生太大变化。CAE用来预训练的效果不错,CAE的编码中只有一小部分对输入的变化敏感,而且对不同的输入,隐藏层对应的敏感单元不同,这种表现跟RBM差不多
目前,有很多种做逐层预训练来发现好特征的方法。如果数据集没有足够的标签,那么这种方法(要用在使用标签之前)对后续的判别微调很有帮助——尤其是有海量无标签数据,但是只有少量有标签数据时。但是如果有标签的数据集很大,那么就没必要用预训练来初始化权重了。不过,如果想让网络更大, 那么预训练还是有必要的
(后面这点视频的核心思想是,如果有标签数据集规模与网络规模匹配,那么预训练和正则化就不太必要。但是如果网络规模比数据集规模大很多,预训练和正则化就有必要了)
