无特殊说明,笔记内容均来自老师提供的讲义和胶片
在MNIST上使用TensorFlow
TensorFlow使用tf.nn.conv2d来做二维的卷积操作(此时需要输入是三维)。不同维度输入的卷积操作可以参考Runhani的StackOverflow回答。函数签名为
1 | tf.nn.conv2d( |
其中
input是输入,默认是四维,每个维度按顺序是batch大小(N)、高度(H)、宽度(W)、信道数(C),即shape(input) = (N, H, W, C)(对应于data_format参数值'NHWC')filter对应CNN的卷积核(也就是前面理论部分所讲的滤波器),其维度也是四维,不过是高度 x 宽度 x 输入信道数 x 输出信道数stride是长度为4的一维数组,代表在input四个维度上的步长。通常设为[1, 1, 1, 1]或[1, 2, 2, 1]。一般情况下,stride[0] == stride[-1] == 1,因为不想跳过任何样本和任何信道padding是补零的方式而非个数,有两个选项。- 如果设置为
VALID,那么当卷积核和步幅的设置使得卷积过程不能完整覆盖输入时,舍弃输入最右侧(或最下侧)的内容。根据相关StackOverflow问题的讲解,考虑最简单的1维卷积的情况,假设输入长度为13,卷积核大小为6,步幅为5,那么第一次卷积操作所“看”的范围是1-6,第二次是6-11,此时再移动卷积核不能覆盖剩下的数据,到此为止,输入的最后两个元素被丢弃 - 如果设置为
SAME,那么会对输入补0,使得输入可以被卷积核按照设定的步幅完整覆盖。补0的原则是左边和右边补的0尽量一样——如果要补的0是奇数个0,在右侧多补一个
- 如果设置为
dilations是理论讲义里提到的膨胀系数。1.4版本里尚未引入这个参数
其它卷积函数,例如depthwise_conv2d和separable_conv2d,可以参考文档
课程讲义中给出了一个使用预定义卷积核做计算的例子,不过这种场景在实际应用中估计很难遇到,大部分卷积核都是训练得出来的(不要忘记卷积核的本质,它就是一组权重)
因此,为了让例子更加贴近实际,这里讲解对MNIST数据集使用TF构建CNN的方法。这里使用的体系结构是两个(卷积+ReLU+最大池)的组合,然后跟两个全连接。具体的体系结构如下图所示
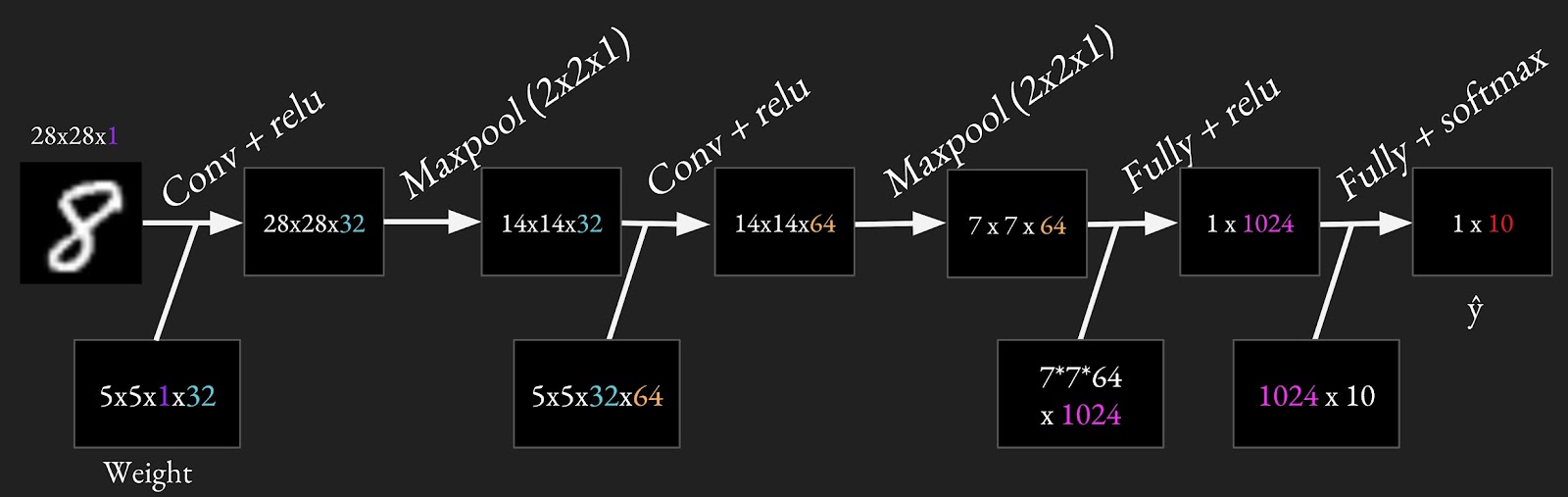
由于很多事情(例如最大池、conv)都要做多次,因此需要设计可复用的代码,而且需要使用变量域来让我们可以在不同的层使用名字相同的变量。通常是每层都创建自己的变量域
定义卷积层
具体实现时,通常把conv和随后的非线性变化ReLU实现在一起
1 | def conv_relu(inputs, filters, k_size, stride, padding, scope_name): |
个中维度计算可以参考前面的理论讲解
定义池化层
可以直接使用TF中的tf.nn.max_pool来完成
1 |
|
定义全连接
与前面介绍的基本前馈神经网络定义方法无异
1 | def fully_connected(inputs, out_dim, scope_name='fc'): |
构成最终代码
将上面的各个函数组合起来可以得到完整的代码。讲义里给出的是预测的图,训练的图应该是类似的,只不过加了定义loss和优化器的部分(然而GitHub上的代码并没有像上面一样良好地组织)
1 | def inference(self): |
tf.layers
前面的各层定义还是有些麻烦,实际上,TensorFlow提供了一种更简单的手段,就是直接使用在tf.layers里定义的各种层
1 | conv1 = tf.layers.conv2d(inputs=self.img, |
注意在使用tf.layers.dropout做dropout时,需要指明现在是在训练还是预测。回忆dropout的核心思想,其仅在训练时会随机丢弃一部分神经元,而预测时不会
1 | dropout = tf.layers.dropout(fc, |
