Hopfield网
本讲开始介绍的神经网络和传统的前馈神经网络不同,它们的性质都是由某个全局的能量函数推演而来,因此称为基于能量的模型。Hopfield网络是其中最简单的一种,由二元阈值的单元组成,单元之间有循环连接。通常来讲,带有循环连接和非线性神经元的网络不太好分析,因为其行为比较难以捉摸:它们可以陷入稳态,可以振荡,甚至可以陷入混沌(除非你知道无限精度的初始状态,否则无法预测不远的将来的状态)。不过,研究发现如果连接是对称的,那么就存在一个全局的能量函数。整个网络的每个二元配置有一个能量。所谓二元配置指的是,网络中的神经元的可能取值有两种,为每个神经元设置其中一个值。如果为阈值的决策规则设置了正确的能量函数,网络的能量会一直下降。如果持续使用该规则,最后会达到一个能量最小值
因此,能量函数的设置非常重要。某个配置的全局能量是若干局部贡献量的总和,而每个“贡献量”由连接权重和两个神经元的二元状态来决定。也就是说,能量函数的定义为 \[ E = -\sum_is_ib_i - \sum_{i<j}s_is_jw_{ij} \] 注意能量越小越好,所以这里加了负号来做限制。\(s_i\)的取值是0或者1(或者在另一种Hopfield网里是-1或1)。有了二次能量函数的定义,每个单元就可以计算改变自身状态会改变多少能量。为此,需要定义能量差(energy gap)的概念,该值实际上就是关闭神经元\(i\)和打开神经元\(i\)两种情况下能量的变化量,即 \[ {\rm Energy\ gap} = \Delta E_i = E(s_i=0) - E(s_i = 1) = b_i + \sum_js_jw_{ij} \] 在Hopfield网中,寻找最小能量通常使用一种顺序迭代的方法:从某个随机状态开始,以随机次序每次更新某一个神经元:看它取哪个状态能量能变小,就让它处于哪个状态。注意这里不能使用节点同时决策的方法,因为如果同时并行更新状态,会导致周期为2的振荡出现。如果在并行更新状态的同时还加入随机的等待时间,也就是说,某个节点更新完状态以后不通知其它节点,而是等待随机长度的时间以后再进行下一次更新,那么这种振荡一般就不会出现
Hopfield认为,这种基于能量,能稳定在某个能量最小值点的模型适用于存储记忆力。使用上述的状态决策规则,可以把部分正确的记忆内容扩散到所有节点,清除掉一些错误的或者不全面的记忆。因此,可以在只知道一部分内容的情况下访问某一项内容。Hopfield网的鲁棒性很强,在硬件出现损坏的时候也可以正常工作,而阈值决策规则的作用此时就像是古生物学家从几根骨骼化石复原出一只恐龙一样
Hopfield网的记忆存储规则也比较简单。如果激活值使用1或者-1,那么将连接两单元的权重加上两神经元状态的乘积就可以,即 \[ \Delta w_{ij} = s_is_j \] 这种更新方法的好处是完全是在线更新,遍历过数据一遍就能得到结果,因为它并不是由误差驱动的,不需要将预测值与真实值比较,然后根据比较结果做微调。但是,这是一把双刃剑,带来的弊端是这种存储方法效率不高。如果状态是0-1值,更新方法略为复杂,但是计算起来还算简单,为 \[ \Delta w_{ij} = 4\left(s_i - \frac{1}{2}\right)\left(s_j - \frac{1}{2}\right) \]
处理伪极小值
Hopfield网的存储能力是一个问题。对一个有\(N\)个节点,全连接的网使用前面的存储规则,网络的容量大概是\(0.15N\)的记忆内容。也就是说,如果有\(N\)个单元,每个单元有两种取值,在有两个单元的记忆开始出现混淆之前,可以存储的记忆数量大概是\(0.15N\)。每个记忆都是\(N\)个单元的一个随机配置,所以有\(N\)比特信息,因此Hopfield网能存储的信息总量是\(0.15N^2\)比特。也就是说,计算机使用了\(0.15N^2\)个比特来存储权重,因此这种分布式记忆+局部特征最小化的方法难以使计算机有效利用其存储能力:网络中一共有\(N^2\)个权重和偏置,存储\(M\)个记忆以后,每个连接权重的取值是\([-M, M]\)之间的一个整数(因为假设初始状态是-1或1,每存入一个记忆以后权重增1/减1),因此存储所有权重和偏置理论上需要的比特数是\(N^2\log (2M+1)\)
所以是什么限制了Hopfield网的能力呢?每次要记住的配置时,都希望可以创造一个新的能量最小值。如下图所示,对某两个二元配置,理想状态是学到两个最小值点,一个是蓝色的,一个是绿色的。不过实际上,由于两者很近,因此最后会发生混淆,两者合并成一个红色的,更小的最小值点,但是不能对这两个二元配置作区分(这部分参考了知乎问答:关于Hopfield神经网络 )。这种相邻最小值点的融合现象称为“伪最小值点”(spurious minima)
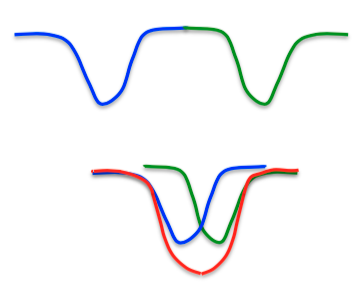
Hopfield、Feinstein和Palmer等人提出了一种应对策略:让网络从一个随机初始状态开始,做一些“忘却”(unlearning)操作。也就是说,不管它处于什么状态,反着用前面提到的存储规则。以前面的图为例,假设现在处于红色的峰值点,经过一些“忘却”以后,就可以脱离这个点,得到了两个独立的最小值,进而增大记忆量。这种方法实践中管用,但是发明者没有做出比较好的原理分析。Francis Crick和Graham Micherson认为忘却法与快速眼球移动睡眠(REM睡眠)的过程很像(具体解释略去)。不过,关于忘却法的另一个问题是,应该忘掉多少东西?实际上,忘却的内容也是使用数据拟合模型这一过程的一部分。如果使用最大似然法拟合这个模型,忘却的过程会自然而然地出现,因此关键问题是提出一个合适的代价函数
在具体介绍忘却法的代价函数之前,先看一看物理学家是如何增强Hopfield网能力的。Elizabeth Gardner提出了一种方法,就是不像之前那样只遍历一遍数据集就存一个向量,而是循环遍历多次训练集。这样,牺牲的是在线学习能力,得到的是更有效的存储。整个训练过程有点像感知机的收敛过程:让整个网络先进入到某个记忆状态,然后单独来看每个单元,判断给定所有其它单元状态的情况下,该单元是否展现了想要的状态。如果结果为“是”,那么让其输入的权重不变;否则按照收敛过程指定的权重更新规则更新权重。这种方法被统计学家称为“伪似然法”。不过Hopfield网中的权重都是对称的,因此对每个权重需要获得两组梯度然后求均值
带有隐藏单元的Hopfield网
Hopfield网包含了两个核心想法:首先,如果网络中的神经元只有两个可能取值,而且连接是对称的,那么就可以找到一个局部的能量最小值;其次,局部的能量最小值可能对应于某些记忆。不过,有另外一种寻找局部最小值的方法,就是不再让网络存储记忆,而是让它对输入构造一些解释。此时,输入由一些可见单元表示,解释由隐藏单元构成。也就是说,此时对输入的解释是隐藏单元上的一个二元配置,整个系统的能量表示这个解释有多差,因此目标是让隐藏单元进入比较低能量的状态
举个例子,当你看到图片里的一条二维的线,它应该是由什么样的三维物体的边缘所投影出来的?实际上,它可能对应了很多不同的三维物体,因为投影时边缘两端的深度信息都已经丢失了。而且,如果若干物体都放在一起,它们之间存在相互遮挡,那么你能看到的其实也只是一条线
假设现在有若干张图片,每张图片里面有若干条线。可以建立一组神经元,每个神经元对应图中的一条线。由于对任意一张图片,很难包含所有的线,因此对给定的一张图片,只有若干几个神经元能够被激活。这些神经元是输入神经元。然后,对所有三维物体的线或边缘,也对应建立神经元。由于一条二维线可以对应若干三维物体,因此对某个被激活的输入神经元,可以与其所有对应的隐藏神经元建立联系
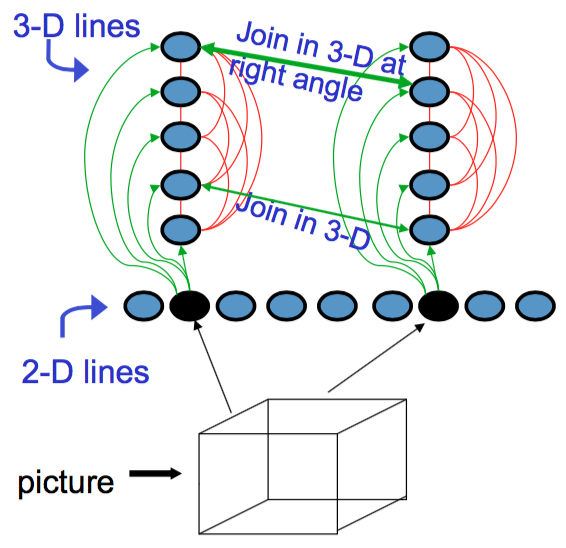
上图给出了一个示意图。这里,输入神经元与隐藏神经元之间的绿色连线表示两者存在可能的对应关系,每个连接都共享相同的权重。由于一条二维线段只对应于一种可能的三维物体,因此这些隐藏神经元之间彼此还存在竞争关系,以红线表示
接下来,要建模的是不同输入单元对应的两组隐藏单元之间的关系:图片中两条二维直线相交,通常意味着两个对应的三维物体在交点处有同样的深度,因此可以建立两个隐藏单元之间的联系(上图中连接两隐藏神经元的细绿色箭头)。除此以外,如果三维物体之间不仅相交还相互垂直,那么就给一个比较强的连接。这样,在建立了隐藏单元与输入单元的连接,以及隐藏单元之间的连接以后,就可以对某个输入图像做出解释
如果决定使用低能量的状态来对输入做出解释,相对应的会带来两个问题:首先,如何避免隐藏单元陷入比较差的能量函数的局部最小值?第二个更难的问题是,如何学习出这些权重,尤其是体系结构中没有监督器的情况下?
使用随机单元以改进搜索
Hopfield网做出的决策总是向着降低网络能量这一目标前进(如果不改变单元状态,那么能量保持不变),因此,很难脱离局部最小值。解决方法是加入随机噪声,这样就可以从比较差的极值点离开,尤其是极值点比较浅的时候效果更明显。这里要加入的不是某个固定数量的噪声,更有效的策略是先加入很多噪声,然后对空间做一个粗略探索,找到总体来讲不错的区域,然后减少噪声。这样一来,噪声很大的时候,就可以翻过比较大的壁垒;减小噪声的时候,网络就开始聚焦于附近的最小值。如果噪声降低得很慢,系统就会陷入一个比较深的最小值,这种方法称为模拟退火法
模拟退火法背后的原理是,在物理系统或者使用能量函数的模拟系统中,温度会影响转移的概率:
- 当系统的温度比较高时,粒子向上上升的概率低于向下降的概率,但是低得不多。这样,更容易翻过壁垒,但是即便达到比较深的极小值也不太容易待得住
- 当系统的温度比较低时,粒子移动的概率总体都不大,但是上升的概率远远低于下降的概率。理论上讲,所有粒子最后都会陷入比较深的最小值,但是如果持续在低温环境下运行,粒子也难以从局部最小值走出来
综合以上两种状况,比较好的组合策略是从高温开始,慢慢降低温度
因此,在Hopfield网中引入噪声的做法是将二元阈值单元转化为二元随机单元,让其做出有偏的随机决策,而噪声的数量由“温度”来控制。提高噪声的数量等价于降低所有配置之间的能量差。具体的形式为 \[ p(s_i = 1) = \frac{1}{1+e^{-\Delta E_i/T}} \] 这个式子与logistic回归中用到的等式类似,只不过能量差\(\Delta E_i\)缩小了温度数量那么大的倍数。如果温度很高,那么指数项接近于0,分母接近于2,单元被激活的概率大概为0.5。温度下降时,取决于\(\Delta E_i\)的符号,单元或者是稳定地保持在开的状态,或者是稳定在关的状态。当温度降低到0时,退化为Hopfield网,单元是否被激活由\(\Delta E_i\)的符号决定,此时随机性褪去,单元退化为原始的二元阈值单元。能量差的定义仍然为 \[ \Delta E_i = E(s_i=0) - E(s_i = 1) = b_i + \sum_js_jw_{ij} \] 模拟退火是一种有效避免陷入局部最优,以改善搜索效果的方法,对玻尔兹曼机的提出也产生了影响。但是深入了解它会分散对玻尔兹曼机的注意力,因此这里不再详述。从这里开始,每个单元都是温度为1的二元随机单元,是能量差的标准logistic函数
要了解玻尔兹曼机的学习过程,就要理解热平衡的概念。大多数人都认为,到达热平衡时,系统稳定下来,不再发生任何变化。热平衡大概是这个意思,但是这不意味着每个单元的状态都稳定了。实际上,每个单元的状态还会变化,稳定下来的是配置上的概率分布。我们称稳定在某个特定分布上的概率分布为稳态分布(stationary distribution),稳态分布由系统的能量函数决定。在稳态分布中,任何配置的概率正比于其负能量。理解热平衡的一种直观方法是,假设很多相同的系统构成了一个巨大的混合体,每个系统都有完全相同的能量函数,比如,有一个巨大的随机Hopfield网组成的集合,每个Hopfield网的权重都相等。在这个混合体中,可以定义某个配置的概率为系统中处于这个配置的系统的比例。然后,可以以任何分布作为初始情况,例如可以让所有节点的配置都相同,或者对每种可能的配置,都有相同数量的网络以该配置为初始配置(这样就是均匀分布),然后使用随机更新规则(选择一个单元,检查能量差,根据能量差随机决定是打开还是关闭,然后选择下一个单元,以此类推),最后会达到一个稳态,即系统中每种配置的比例是固定的(如果连接是对称的,最后肯定会达到这个状态)
对此,可以有一个类比。假设在拉斯维加斯有个巨大的赌场,里面有多于\(52!\)个发牌者,每个发牌者拿到的牌都是未开封的,由同一家厂商制造,初始顺序按照标准顺序排好。然后,所有发牌者开始随机洗牌,而且不玩那种把牌变回原来顺序的那种把戏。经过少数几次洗牌以后,可能黑桃K还在黑桃Q上面,也就是说,任意牌堆里还会有一些牌没有忘记自己的初始位置。不过,在经过长时间洗牌以后,所有牌堆的所有牌都会被打乱顺序,此时牌的\(52!\)种排列出现的数量相等,并且每种排列的数量不会随着洗牌的过程而变化
(简而言之,热平衡不是系统内的粒子不动,而是粒子还在动,但是整个系统呈现稳定状态)
玻尔兹曼机如何对数据建模
带有隐藏单元的随机Hopfield网也称为玻尔兹曼机,这种模型擅长对二进制数据建模。也就是说,给定一组二进制的训练向量,可以使用隐藏单元来训练一个模型,这个模型可以对任意二进制向量计算一个概率。这样,可以判定其它二进制向量是否来自于相同分布。一个实际的例子是,假设有一个很大的词表,那么每个类型的文档可以使用二进制向量表示(每一位代表该单词是否出现),进而判断测试数据应该属于哪个类别。也可以使用玻尔兹曼机监测复杂系统,检测异常行为。所有这些应用的背后都是贝叶斯定理:假设有若干模型,每个模型对应一个分布,那么可以使用贝叶斯定理计算给定观察数据对应模型的概率,即 \[ p({\rm Model}_i|{\rm data}) = \frac{p({\rm data}|{\rm Model}_i)}{\sum_jp({\rm data}|{\rm Model}_j)} \] 使用贝叶斯定理时,需要计算模型产生数据的概率。这种做法有两种,一种是先根据隐藏单元的先验分布生成某些隐变量的状态,然后用隐变量生成二进制数组。这种模型称为因果模型(causal model)。在这种模型里,隐藏单元的先验分布一般是独立的,因此每个单元被激活的概率(如果是二元状态)只取决于各自的偏置量。得到隐藏单元以后,就可以使用隐藏层到输出层的权重和偏置,加上logistic非线性变换得到输出层每个单元被激活的概率。因此,对于因果模型,得到某个向量\(\bf v\)的概率是 \[ p({\bf v}) = \sum_{\bf h}p({\bf h})p({\bf v}|{\bf h}) \] 其中\(\bf h\)是任意隐藏单元
不过,玻尔兹曼机不是因果模型,而是基于能量的模型(……),一切真理都定义为可见单元和隐藏单元联合配置的能量,而将能量与概率相联系又有两种方法:其一是让\(p({\bf v}, {\bf h}) \propto \exp{-E({\bf v}, {\bf h})}\),其二是定义为在多次更新所有随机二元单元,达到热平衡以后,网络得到该联合配置的概率。这两种方法本质是一样的。记\(E({\bf v}, {\bf h})\)为可见单元配置为\(\bf v\),隐藏单元配置为\(\bf h\)时网络的能量,有 \[ -E({\bf v},{\bf h}) = \sum_{i \in {\bf v}}v_ib_i + \sum_{k \in {\bf h}}h_kb_k + \sum_{i< j}v_iv_jw_{ij} + \sum_{i,k}v_ih_kw_{ik} + \sum_{k<l}h_kh_lw_{kl} \] 这里\(b_i\)是单元(无论是隐藏单元还是可见单元)\(i\)的偏置值,\(w_{ij}\)是单元\(i\)和\(j\)之间的权重。对同在隐藏层/可见层的单元,需要避免重复计数
由于可见层任一配置的概率\(p({\bf v}, {\bf h}) \propto \exp{-E({\bf v}, {\bf h})}\),因此通过上述方法得到\(-E({\bf v},{\bf h})\)以后可以使用类似softmax的方法算出概率值 \[ p({\bf v}, {\bf h}) = \frac{e^{-E({\bf v}, {\bf h})}}{\sum_{ {\bf u}, {\bf g}}e^{-E({\bf u}, {\bf g})}} \] 其中分母也被物理学家称为“划分函数”(partition function)
类似地,可以求出可见单元某个配置的概率 \[ p({\bf v}) = \frac{ \sum_{ {\bf h}}e^{-E({\bf v}, {\bf h})}}{\sum_{ {\bf u}, {\bf g}}e^{-E({\bf u}, {\bf g })}} \] 如果玻尔兹曼机对应的网络太大,那么隐藏层+可见层所有单元可能的配置数会非常多,因此计算完整的划分函数值不太现实。此时可以使用MCMC方法来抽样,即从某个随机的全局配置开始,随机选取某个单元,根据能量差随机改变状态。这样持续下去,等到马尔可夫链达到稳定分布,就得到了模型的一个抽样,这个抽样的概率\(p({\bf v}, {\bf h})\)正比于\(\exp \{ -E({\bf v}, {\bf h})\}\)
另一个问题是,给定一个数据向量,怎么从隐藏配置的后验分布上获得一个样本?由于隐藏配置的集合也是指数量级的,因此仍然使用MCMC方法。与前述过程唯一不同的是,这是要保证可见单元不变,对应于给定的数据向量,只改变隐藏节点的状态。这时,可以理解为每个隐藏配置都是对观察数据的可见配置的一个解释,更好的解释能量更低
