对序列建模
当使用机器学习方法对序列建模时,通常是要把一个序列转化为另一个序列。例如,想把英语单词序列转化为法语单词序列(机器翻译),或者是将声音信号转化为单词的文本序列(语音识别)。有的时候,并没有一个单独的目标序列,在这种情况下,可以通过试着预测输入序列的下一个项(item)来获取一个教学信号,因此此时目标输出序列就是一步之后的输入序列——对于时间序列来说,这种预测是很正常的。不过对于图像则不然,预测下一个像素点是什么感觉应该是没有什么意义
当预测序列中的下一个项时,实际上有监督学习和无监督学习的界限已经变得模糊了:预测下一项内容时,使用的方法是有监督学习方法,但是并不需要独立的教学信号,因此这里又存在一些无监督的味道
在介绍RNN之前,先看一些其它对序列建模的模型。其中一种不需要额外内存的方法叫自回归模型,其原理是使用前面一些项的值做一些加权平均,来预测接下来的这一项。对这种算法稍加修改,加入隐藏单元,可以得到一个前馈神经网络,例如Bengio的第一个语言模型就使用了这样的原理
其他一些模型可以让其隐藏状态有一些内部的动态变化,这样这些隐藏状态可以根据自身内部的动态性演化,并产生观察结果。通过该机制,模型可以在隐藏状态里存储信息,并保留比较长的一段时间。如果隐藏状态的动态性是带有噪声的,而且它通过隐藏状态生成输出的过程也是带有噪声的,那么通过观察这种生成模型的输出是不可能推断其具体的隐藏状态的,只能推测在所有可能隐藏状态向量的概率分布,而这个过程通常比较难。不过对某两种特殊的隐藏状态模型,它们的隐藏状态分布是可计算的
第一种模型是线性动态系统(linear dynamical systems),在工程界得到了广泛应用。下图给出了该模型的示意图
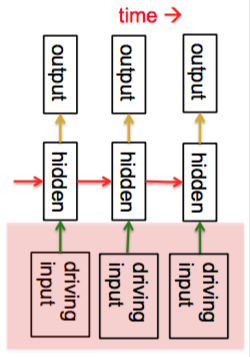
这种生成模型的隐藏状态都是实数,有线性动态性(由红色箭头表示),这种动态性带有高斯噪声,所以隐藏状态会按照一定概率演化。模型的底部是驱动输入,可以直接影响隐藏单元,而隐藏单元会决定输出。因此为了预测系统的下一个输出,就需要能推断隐藏状态。这里隐藏状态可以被推断的关键原因是因为假设了动态性是高斯噪声,满足高斯分布,而高斯分布的一个特点就是对高斯分布做线性变换的结果还是一个高斯分布,因此给定观察结果(输出)时隐藏状态的分布也是高斯分布(实际上,是一个完全协方差高斯分布,即协方差矩阵元素都不为0)。对于这类问题,可以用卡尔曼滤波(Kalman filtering)来解决
第二种模型是隐马尔可夫模型(hidden Markov model, HMM),它使用的是离散分布,基于离散数学,因此广受计算机科学家喜爱。下图给出了HMM的示意图
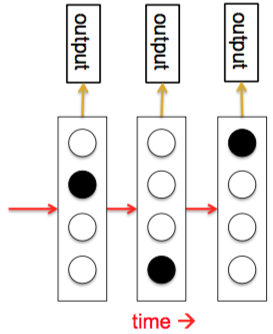
在HMM中,隐藏状态是\(N\)个可能值中的一个,状态之间的转移符合某种概率分布,可以组成一个概率矩阵\(\rm M\),称为转移矩阵。例如,从状态1转移到状态2的概率是\({\rm M}_{12}\)。而且,输出模型也是随机的,因此系统所在的状态不能完全决定其所产生的输出,也就是说,内部状态“隐藏”在这个概率矩阵的背后。为了预测HMM的下一个输出,需要推测其可能位于哪个隐藏状态,对此可以使用一种动态规划算法,通过观测值可以推出隐藏状态的概率分布矩阵。得到概率分布矩阵以后,就可以得到HMM算法。这种算法在2012年左右是语音识别算法的首选(也是输入法引擎算法的首选)
HMM有一个非常基本的局限性:它每次产生数据的时候,都会选择从\(N\)个隐藏状态中选择一个。所以每个隐藏状态中储存的时间信息最多有\(\log N\)位。假设现在要使用HMM生成一句话,已经生成了前一半,要生成后一半,则它对前一半的记忆是通过其在\(N\)个隐藏状态中的哪一个来体现,所以只有信息中的\(\log N\)位。为了让句子的后一半与前一半相协调,则后面的句子的语法要与前面匹配(性、数、格一致),语义要与前面匹配,语调、口音、音色等等都需要匹配。所以如果需要使用HMM来生成一个句子,那么隐藏状态需要覆盖所有这些信息。假设这些信息一共有100位,那么HMM就需要\(2^{100}\)个状态!
因此就需要循环神经网络(RNN)来解决这个问题了,它可以更有效地“记住”信息。其有两个特点:
- 分布式隐藏状态。也就是,同一时刻可以激活多个不同的单元,因此它可以同时记住几件事情
- 非线性。隐藏状态不再需要以线性方式演化,因此系统可以更加复杂。在有足够神经元和时间的情况下,它几乎可以计算任何事情
除此以外,线性动态系统和HMM都是随机模型,有一些噪声。但是模型真的需要这样吗?实际上,这两个随机模型在隐藏状态上的后验分布都是确定函数,概率分布都是一些确定的数字。而在RNN里,可以认为这些数字构成了RNN的隐藏状态,就像这些简单随机模型中的概率分布一样
RNN的行为可以展现出如下特点:
- 震荡性,因此RNN可以适用于动作控制(motion control)。例如可以求出走路时的步幅
- 可以停留在某个稳定点(point attractor)上,因此可以适用于从某些“记忆”中获取信息(Hinton没有展开这一块,所以不是很明白。论坛里助教也并不理解这个概念)。可以理解为,你有一些大致的想法,大概知道想要获取什么,然后系统就可以停留在某个稳定点上,这些稳定点就对应于你想要获取的信息
- 混沌性(chaotically)。通常混沌性对信息处理来说并不是一件好事,但是在某些环境下,如果你正在与一些更聪明的对手作对,无法智取对方,那么随机出招可能反倒是个好事。达到这种随机性的方法就是让行为体现出混沌性(这又是什么鬼……)
RNN的关键问题是,计算能力太强,因此难以训练
## 使用反向传播算法训练RNN
假设现在有一个简单的RNN,由三个相互连接的神经元构成。连接之间有一个时间单位的延迟,网络的时钟每次走一个时间单位。要理解如何训练一个RNN,关键问题是要看到RNN的本质还是前馈神经网络,只不过是要将网络按照时间展开
在第0时刻,RNN有一个初始状态,通过同样的权重一点一点得到接下来各个时刻的状态。也就是说,RNN是一个每层权重都限制为相同权重的前向网络。在前面讲解CNN时,我们看到过反向传播如何在存在某些(线性)约束的情况下进行,即先像往常一样计算梯度,然后修改梯度来满足限制条件。对于RNN也是一样的,即先计算\(\frac{\partial E}{\partial w_1}\)和\(\frac{\partial E}{\partial w_2}\),然后对\(w_1\)和\(w_2\)都使用\(\frac{\partial E}{\partial w_1} + \frac{\partial E}{\partial w_2}\)
这样,就可以得到RNN的反向传播算法,不过这一算法更常见地是被称作“随时间推移的反向传播算法”(BackPropagation Through Time,BPTT)。因此, 可以从时间的角度来思考这个算法:正向的一趟计算在每个时间步都对所有隐藏单元的行为做一次计算,然后构建起一个栈;反向的一趟计算在每个时间步计算错误的偏导数,然后一步步把这个栈拆解掉(这也是为什么这个算法被称为是“随时间推移的”的原因)。在反向传播以后,就可以把所有不同时间步对各个权重的偏导数加起来,通过一定的比例变换最终让每层权重相同
对于RNN,还有一个初始状态的问题。尽管可以将所有初始状态都设定成一个默认值,但是这样网络的效果不会特别好。事实上,也可以像学习权重那样学到网络中的状态,即先对所有非输入节点设定一个随机的初始值,然后每次反向传播也计算误差函数对状态的梯度,使用梯度下降来对状态进行修改。RNN中的初始状态有很多种初始化方法
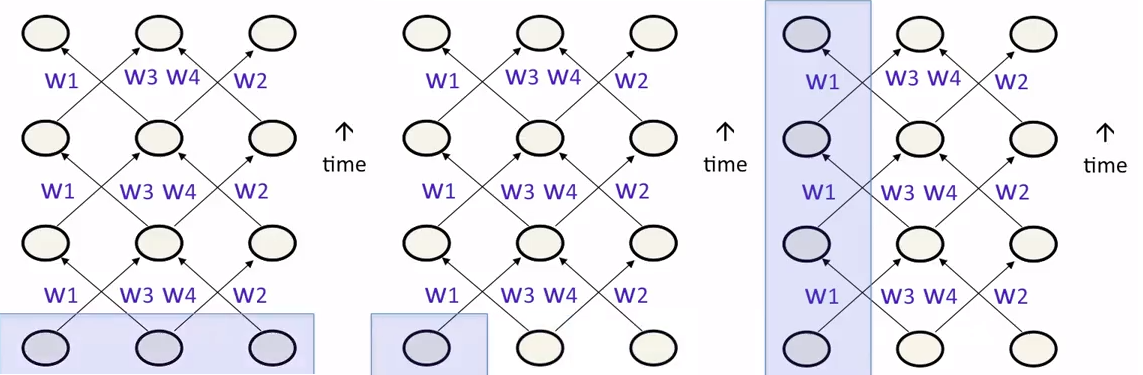
- 上图左给出的方法是先指定所有单元的初始状态。如果把RNN看作权重受限的前向网络,这种做法比较自然
- 上图中给出的方法是指定某几个单元的初始状态
- 上图右给出的方法是对某几个单元指定它们在各个时间步的初始状态。如果要解决的问题是对顺序数据的建模,那么这种方法更自然
类似地,RNN的学习目标也有很多种选择方法
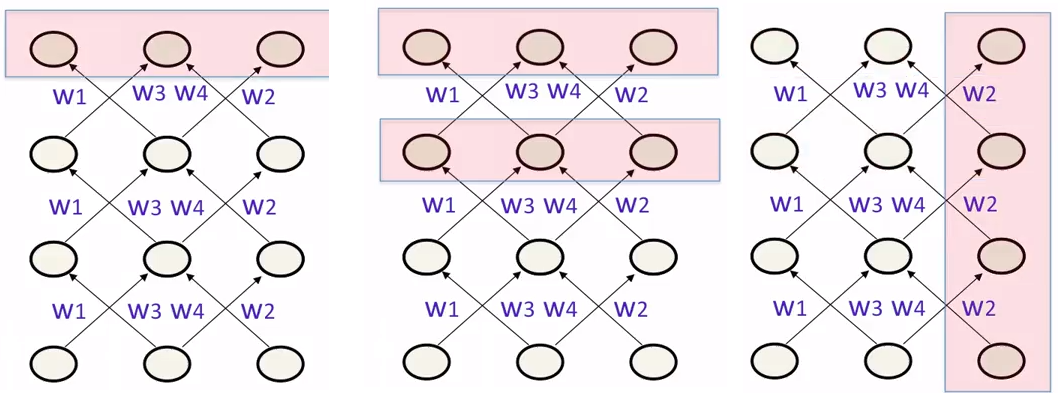
- 上图左给出的方法是选择所有单元的最后状态。如果把RNN看作权重受限的前向网络,这种做法比较自然
- 上图中给出的方法是选择所有单元最后几个时间步的状态。这样做有助于学习到某些“稳定点”(attractor)
- 上图右给出的方法是指定某些单元为输出单元,输出这些单元在每个时间步的最后状态。如果要提供连续输出,这种方法比较自然
示例:训练一个简单的RNN
本节我们来考虑这样一个问题:如何训练一个神经网络,使得其输入为两个二进制数字,输出它们的和(也是二进制表示)。这个问题是可以用普通的前馈神经网络解决的,但是做起来比较麻烦:首先,需要预先确定加数、被加数以及和的最大位数。此外,更重要的是,对两个输入不同位上的做法是不能泛化的。确切说,对于两个输入,前面的处理逻辑和后面的处理逻辑使用不同的权重,因此两者的逻辑不能自动泛化。这意味着,使用前馈神经网络不能优雅地解决二进制加法问题
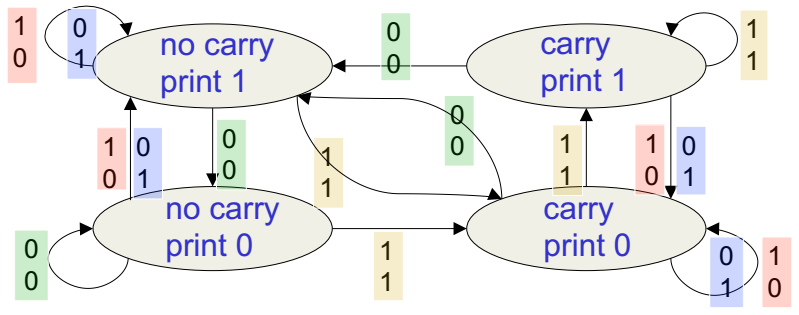
上图给出了一个解决二进制加法问题的有限状态自动机。系统在每个时刻都会处于图中的某个状态,然后接受下一列的两个数,根据输入决定状态的转移,进入到某个状态时则做相应的动作。假设现在自动机在右上角的状态,它会输出1,同时打开进位器。下一栏的两个数都是1,那么它会进入到相同的状态,输出1。但是如果下一栏的两个数一个是1一个是0,则它还会打开进位器,但是进入到右下角的状态,输出0;如果下一栏的两个数都是0,那么它关闭进位器,进入到左上角的状态,输出1。这意味着解决二进制加法的RNN需要有两个输入单元和一个输出单元,对应于在每个时刻接受两个输入位产生一个输出位
需要注意的是,网络的输出对应于两个时间步之前的输出。要延迟两个时间步的原因是,网络需要一个时间步来根据输入更新隐藏单元,另一个时间步来从隐藏状态产生输出。因此网络最少只需要三个隐藏单元,这三个单元是双向全连接的,每个方向的权重不同。这样的结构使得网络可以根据时刻\(t\)的隐藏状态推断出时刻\(t+1\)的隐藏状态。从输入单元到隐藏单元是普通的前馈模式,这样隐藏状态可以获取输入;类似地,从隐藏单元到输出单元也是普通的前馈模式,以产生最终输入
由于RNN能够完成二进制加法操作,因此其实际上这三个隐藏单元学到了四种不同的模式,对应于前面有限状态自动机的四个节点。注意有限状态机节点对应的不是RNN隐藏节点,而是RNN隐藏节点的活动向量(笔者注:这个名词,对应英文activity vector,似乎很少在其他课程或者文献中见到。但是Hinton前几天发表的Capsule Network也用了这个概念,不知道是不是他自己创造的)——在每个时刻,有限状态自动机只能处于某个确定的状态,而RNN的隐藏单元也只能有一个确定的活动向量。因此RNN可以模拟有限状态自动机,但是表示能力是指数级地增强:有\(N\)个隐藏单元的RNN可以有\(2^N\)个可能的二进制活动节点(不过只有\(N^2\)个权重)。因此如果输入流有两个独立事件并行发生,则有限状态自动机需要将自己的状态数平方,但是RNN只需要将自己的隐藏单元数翻倍
为什么训练RNN很困难
RNN训练的难点在于,其正向传播过程和反向传播过程是有差别的。前向传播的过程中使用的是“挤压”函数(squashing function),例如logistic函数,来防止活动向量爆炸。但是反向传播是线性的,由前向传播时的结果决定,因此会面临线性系统面临的问题:如果权重都很小,那么梯度就会小,连乘以后会变得更小。那么,由于RNN是按时间展开的,所以这意味着经过几个时间步的传递,比较早的节点就得不到什么错误更新的信息了。同样的道理,如果权重都很大,那么梯度就会爆炸。不过,对于传统的前馈神经网络,除非这个网络特别深,否则不会出现这么糟糕的情况
上面说的这两种情况,分别对应于梯度消失和梯度爆炸两种情况。小心地初始化权重可以有效地解决这个问题,不过即使这样也很难让当前的输入输出利用其很多个时间步之前的信息,也就是说,普通的RNN结构很难处理长距离的依赖关系
假设系统中有两个稳定点,要通过RNN学出这两个点,那么,如果初始状态在这两个点附近,则最后的结果肯定是停留在对应的稳定点上,最终状态对初始状态改变量的导数接近0,出现了梯度消失。但是如果初始状态在两个点的交界处,那么无论往哪边偏一点,都会陷入到对应的点上,不同的偏差可能会导致截然不同的结果,也就是出现梯度爆炸
为了解决RNN难以学习长距离依赖的问题,大概有四种解决方法
- 使用一种叫做长短期记忆(Long-Short Term Memory, LSTM)的方法。这个方法在下一节介绍,简单来说,原理是修改神经网络的体系结构
- 使用更好的,可以处理非常小梯度的优化器。这个方法在下一章介绍
- 小心的初始化输入层到隐藏层的权重,非常小心地初始化隐藏层之间,以及隐藏层到输出层的权重,保证隐藏状态是一个弱耦合振子的大资源库。对于这样的网络,送进一个输入序列以后,会产生长时间的“回响”,通过回响来记住在输入序列里发生了什么。这种网络称为回声状态网络(Echo State Network, ESN)。它学到的只是隐藏层到输出层的连接
- 使用动量以及ESN里用到的初始化方法,学习网络中的所有连接
对RNN的改进
长短期记忆(LSTM)
个人感觉,Hinton这一块讲得不是特别好,所以视频被我跳过了。具体内容可以参考这篇闻名遐迩的博客。之后的博客里我可能也会再做一些介绍
