为何物体识别很困难?
尽管人类在计算能力上能被计算机甩开好几百条街,但是有一项任务做起来却是得心应手,比计算机高到不知道哪里去了。这项任务就是物体识别——人类是如此擅长这件事情,甚至不知道做起来有什么难点。但是同样的事情,机器做起来可谓是困难重重
- 难以从图片中把要识别的物体分割出来(segment out)。在现实生活中,我们可以在移动中寻找线索,也可以通过肉眼得到三维的立体线索,但是这些线索在静态图片中都不能用。因此,仅凭图片,很难分清哪些东西属于同一个物体。此外,目标物体的某一部分可能隐藏在其他物体的后面,因此难以看到其全貌
- 其次,像素密度受光的影响非常大,这种影响程度甚至等同于物体本身对像素密度的影响程度。假设某种黑色表面的物体置于明亮光中,其像素密度可能比置于暗光下的白色物体的像素密度还要大。而要识别物体本质上是对数字的操作,这些数字就是像素的密度
- 物体的形态还会变化,有同样名称的两个物体其形状可能不同。例如同样是手写数字2,有的人在底部会写成横,有人会绕个弧
- 有些物体类别的定义是由功能决定(affordance,功能决定性),而不是由外观决定的。例如椅子实际上是一种坐具,因此太师椅、藤椅等等都可以算作是椅子,虽然它们的形状不同
- 观察物体的角度可以不同。在现实生活中,人类可以根据不同角度的观察结果辨识出一个三维物体,但是同一个物体观察的视角不同形状也会不同,输入的信息(在物体识别问题中是像素点)就会发生比较大的变化,使得传统机器学习方法难以处理。举个例子,假设现在要做一个简单的机器学习模型,输入数据的两列应该是病人的年龄和体重,但是有的人填数据的时候填错了,“年龄”一栏填的是体重,“体重”一栏填的是年龄,那就必须在训练模型之前先把这种混乱的数据处理掉。这种现象称为“维度跳跃”(dimension hopping)
如何使算法不对视角敏感
被观察的物体会因视角不同导致形状发生变化,使得同一个物体送进算法的数据(像素)是不同的,这是计算机视觉面临的一个主要难题,而且现在(2012年)暂时还没有广泛被接受的解法。目前主流的做法分为四种
- 使用冗余的,表示不变性的特征
- 把要识别的物体用一个框框住,然后使用正则化的像素
- 使用重复特征,然后做池化
- 使用相对于镜头或屏幕不变的部分
第三种方法也称为卷积神经网络(Convolutional Neural Nets, CNN),将在第三节介绍。第四种方法将在本课程后面部分介绍。本节主要讲述第一、二种方法
使用不变性特征
这种方法的意思是,图像中有一些特殊的特征,即便是在图像被变换(翻转、平移或缩放)后这些特征本身也是不变的。因此应该提取大量的、冗余的这种特征。例如,假设图像中某两条平行线中间有一个红点,这种特征肯定不会因图像变化而变化
有了这些特征以后,接下来的问题是如何把它们组合起来。实际上的解决方法很简单,就是不需要组合,不需要直接表示特征之间的关系,因为这些关系会被其他特征所捕捉。因此,实际上只需要把这一堆特征送进模型,因为模型之间有交叠和冗余,因此其中某个特征会说明其他两个特征是怎么关联的
不过,使用不变性特征做物体识别时,最重要的一点是,不要把来自不同物体的几部分组合起来
合理归一化
第二种方法称为合理归一化(judicious normalization)。例如,下面这个R经过上下颠倒以后在周围加了个框。然后,就可以在框上标明顶部(top)和前部(front)
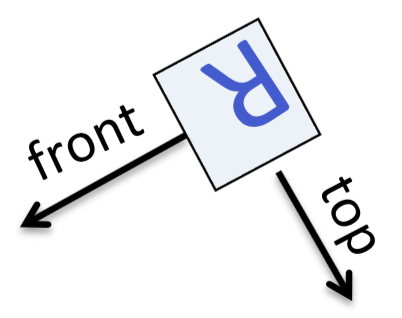
这样一来,就可以说R在框的后部有一个竖线,在顶部有一个弯,等等。无论视角怎么变,如果这个框画对了,这些位置特征相对于这个框来说就是不变的,物体的同一个部分总会有相同的归一化像素。需要说明的是,这里“框”是一个抽象概念,实际使用时不一定非得是长方形
但是这种方法的难度在于,很难选择这个框,原因如下
- 分割物体时,可能会有误差
- 物体的一部分可能会被其它东西挡住
- 物体的朝向有时候会与我们经常看到的朝向不同。例如上面这个R就是倒着的。而且,在标记上面这个边框哪里是上面,哪里是前面时,用到了一些先验知识。如果现在要做的是手写字母识别,有个人写了一个蹩脚的小写d,然后在上面画蛇添足加了一笔,那么再画框的时候前后和上下与上面的例子就是相反的了。这意味着,要想正确画框,就要先认出图像的形状;要想认出正确的形状,就要先画对框。这就成了一个鸡生蛋蛋生鸡的问题
接着上面的最后一条扩展一下,一些神经科学家认为人们看到任何方向不对的物体时都会在心中有个旋转的过程,但是Hinton认为这纯属无稽之谈:人们一眼看上去就知道是R,而且是上下颠倒了,只有这样才能知道怎么把这个字母正过来。真正要用到心算的时候是判断一个物体的“手性”(即是否镜像)时
因此,可以引出一种称为“蛮力正则化”的方法,即在训练时使用正规的,正确分割的物体,因此可以在训练识别器的时候使用合理归一来把物体框起来。测试时,对零散的物体,使用各种可能的框去框物体。这种方法在2012年时是一种比较受欢迎的方法,因为用它来检测未分割图片中角度比较正的物体(例如人脸和房子)比较好用。进一步地,尝试所有可能的框时,可以使用一种粗糙的网格法。这样识别器就可以处理一些变化特征,例如位置的变化和缩放信息
用于手写数字识别的卷积神经网络
卷积神经网络的灵感来自于重复特征。由于物体总是移动,其表现形式(像素点)也不同,因此如果某个特征检测器在图片的一部分起作用,它在别处可能也能用上。因此,可以在所有不同的位置构建很多相同特征检测器的不同拷贝
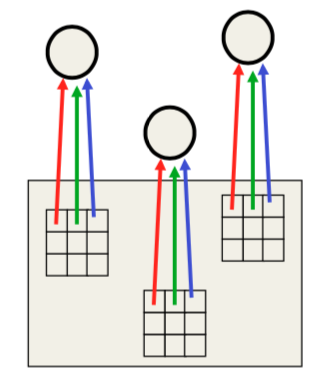
上图给出了三个特征检测器,三者都是互相重复的。每个检测器都有9个权重,对应于9个像素点,而且对每个检测器,它们的权重都相同。例如,对于三个引出红箭头的格子,它们使用的权重都一样。这种跨区域的重复性可以极大减少要学习的参数数量。记检测器的权重为\(w\),检测器检测的区域为\(x\),则\(x\)通常被称作输入,\(w\)通常被称作核函数,它们的输出\(x \ast w\)有时被称作特征映射
上面这种特征检测器可以看做是图片中某个局部区域的一种映射,也可以看作是一种特征类型。为了识别物体,肯定要训练多种类型的特征,这样,图片的每个部分可以被不同类型的特征所表示。重复特征也易于通过反向传播来学习,实际上,对反向传播算法稍加改动就能加入这种权重之间的线性约束关系。具体做法是,先按照往常一样计算梯度,然后修改梯度使得它们满足所受的约束。因此,如果在权重更新之前它们满足线性约束,在这样更新以后约束仍然存在。例如,假设约束条件是\(w_1 = w_2\),同时这两者在权重更新前就相等,那么为了保证权重更新后两者依然相等,就需要使得\(\Delta w_1 = \Delta w_2\)。为此,可以计算\(\frac{\partial E}{\partial w_1}\)和\(\frac{\partial E}{\partial w_2}\),然后令\(\Delta w_1 = \Delta w_2 = \frac{\partial E}{\partial w_1} + \frac{\partial E}{\partial w_2}\),就可以保持这样的约束条件
需要注意的是,重复的特征并不会让被激活的神经元有平移不变性,只不过会让神经元有等变(equivariant)的行为,可以看下图的例子
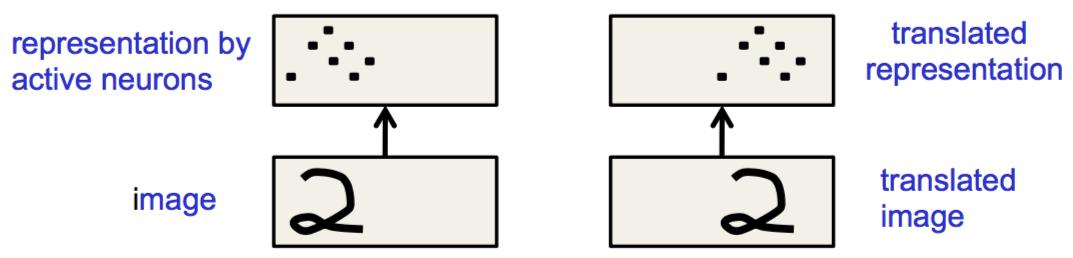
很显然,在这两种情况下,手写数字的位置是不一样的,激活的神经元的位置也是不一样的,但是被激活的神经元展现出来的模式相同。CNN得到的真正的“不变性”是知识的不变性:如果某个特征在训练时对某个区域有用,那么这个特征的检测器在测试时对所有的区域都可用。也就是说,等变的是神经元的行为,不变的是权重
如果想让神经网络对神经元行为取得某些不变性,那么就需要对重复特征检测器的结果做池化(pooling),例如对四个邻居检测器的结果求平均,将得到的这个平均值送入下一层,可以实现一小部分平移不变性。这样做的好处是可以减少下一层接受的输入数量,所以可以产生更多映射,在下一层学习更多特征。不过通常情况下做的池化操作是求最大值(这种池化操作称为最大池)。这样做的问题是经过几层池化可能会丢失物体准确的位置信息,例如,假设要做的任务是检测出有没有人脸,那么经过池化以后大致能看到哪里是鼻子,哪里是嘴,根据粗略的位置,可以做出判断。但是如果要做的任务是检测出这是谁的脸,就不好办了。因为池化操作使得眼睛跟眼睛,鼻子和嘴唇之间的精确距离信息都丢掉了
Yann LeCun团队设计的LeNet是卷积神经网络的一个成功应用,它具有很多个隐藏层,每一层有很多重复单元的映射,而且每一个隐藏层都会对周围重复单元的结果做池化,再将池化结果送入下一层。下图给出了LeNet5的一个例子,其中“子采样层”(subsampling)就对应于现在说的池化层。更多的结果可以参看Yann LeCun的主页 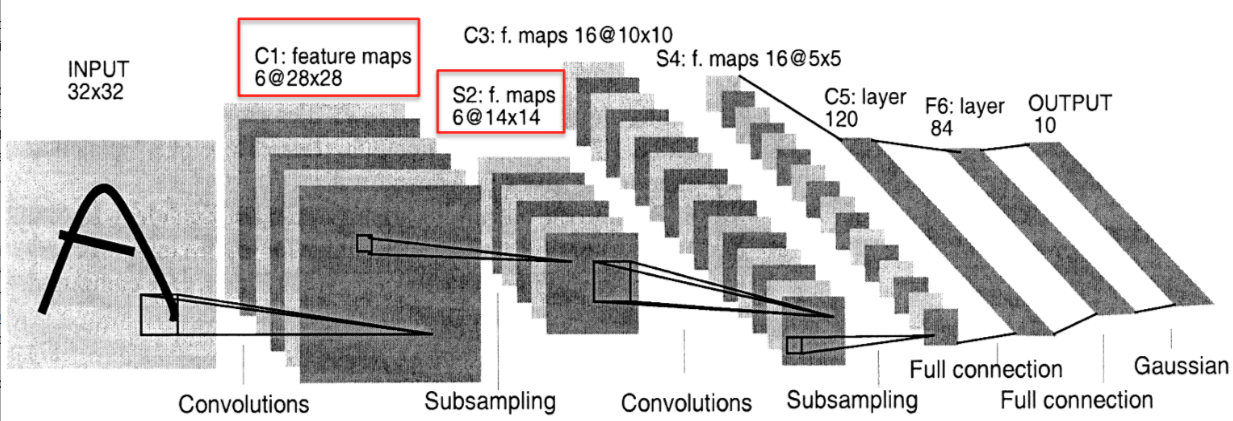
需要注意的是,在设计LeNet时,里面其实也使用到了人类的一些先验知识,例如局部连通性、权重限制、以及选出何时的神经元激活函数等等。另一种方法是使用先验知识构造大量训练数据。当训练数据的数据量变大以后,尽管训练时间会变长,但是优化方法可以帮助网络找到一些聪明的,人类之前想不到甚至没法完全理解的处理方式。将这两种方法(权重共享/池化 + 人造数据)可以通过类似蛮力法的方法比较好地解决手写数字识别的问题。瑞士的一个研究团队可以达到只出现35个错误的成绩,此外,他们还通过训练多个模型然后将模型进行组合的方法,将错误数量压低到25个
这里引出了另一个问题:如果测试集有10000条样本,模型A判断错40条,模型B判断错30条,我们能确定地说B比A好吗?不一定。来看一下下面两个McNemar检验矩阵

对于McNemar检验,着重要看的是红色的两个数据。对于第一种情况,“模型B正确但模型A错误”与“模型A正确但模型B错误”的比例达到了惊人的11比1,这个结果实在是太显著了,因此可以肯定地说B更好。但是对于第二种情况,两者的比例仅为5比3,这样的数据就不显著了,因此没有足够的置信度说B更好
(笔者注:实际上,McNemar检验的计算逻辑要稍微复杂一些。假设模型A正确但模型B错误的测试数据数量为\(b\),模型B正确但模型A错误的测试数据数量为\(c\),McNemar检验先计算的是\((b-c)^2/(b+c)\),然后把这个值看作是自由度为1的\(\chi^2\)分布的值,通过这个值可以看p值。对于上图第二种情况,对应的p值大约为0.1x,不能说有显著性)
用于物体识别的卷积神经网络
尽管卷积神经网络在MNIST手写数字识别上已经取得了很好的效果,但是要想用在实际任务,从一张包含了大量杂乱物体的彩色图片中识别出来目标物体,还是比较难的。这些难点在于
- 要识别的物体有很多种。即便只需要识别一千个类别,目标类别数量也是原来的100倍
- 像素更高。原来是28 x 28的黑白图片,现在要识别的至少是256 x 256的彩色图片
- 真实场景下需要处理的图片是三维实体的二维影像,所以会丢失很多信息
- 手写数字中虽然有笔画交叠(因此需要算法把数字分割开),但是不会出现物体遮挡,在同一个场景里也不会出现多个不同种类的物体,也不会出现光照变化
类似于MNIST,有一个称为ImageNet的数据库可以用来检测物体识别算法的准确程度。图库中有120万张高分辨率的训练图片,他们被人类手工标注成了1000个类别。但是,手工标注的结果并不总是十分可靠,有的图片里有两个不同类别的物体,但是标签只标注了其中一个。因此,ImageNet分类竞赛允许系统对给定图片给出5条猜测,如果人类给出的标记落在这5条猜测中,就算是正确。除此之外,ImageNet竞赛还有一个“定位任务”,因为现有算法都是使用特征“袋”方法(类比于NLP领域中的词袋模型),因此尽管算法对给定图片知道它符合什么特征,也知道里面包含什么物体,但是并不知道目标究竟在哪里。因此,定位任务要求算法不仅能找到目标物体,还要将其框出来。如果给出的框与正确的框的交叠部分能达到50%,就算合格
目前(2012年),计算机视觉系统使用的多是复杂的多阶段系统,这些系统的初始阶段一般是使用是某些数据手动调优少许参数,末尾阶段一般是某种机器学习算法。但是整个系统并不是一个“连贯的”,端到端的学习系统,不能像反向传播那样,让早期特征检测器所使用的参数根据其在最后判断类别时的表现进行自动调整
ImageNet竞赛的一个里程碑式的CNN体系结构是Alex Krizhevsky(Алекс Крижевский)在NIPS2012上提出的网络结构(现在称为AlexNet)。它包括7个隐藏层(不算最大池化层),其中前面几层都是卷积层,这样可以降低计算量。最后两层才是全连接层,这里包含了网络的大部分参数(层与层之间大概有1600万参数),用来寻找前面卷积层提取的局部特征的最优组合
AlexNet在每个隐藏层中使用的激活函数都是ReLU,它们比logistic激活函数训练起来更快,而且表示性更强。此外,它还使用了一种称为“竞争归一化”(competitive normalization)的方法:对某个区域,如果其邻接区域的神经元非常活跃,那么就抑制该区域神经元的活跃程度
AlexNet使用了如下两种方法来提升模型的泛化能力,避免过拟合
- 训练时,在256 x 256的图像上随机选取一个224 x 224的子图,这样可以得到大量数据。另外,对每张图像,还做了一个左右镜像,这种左右的映射不会实际改变物体的外观(除了图像里面是手写笔迹这种情况)。但是,Alex没有使用上下镜像,因为重力是一个很关键的因素。在测试时,它取测试图像四角上224x224的图像和中间同样大小的图像,然后对这五张图像都做一个左右翻转,用总共这十张图片得到是个测试结果,将这些结果组合得到最后的结果
- 使用了一种称为dropout的新型正则化方法。这种方法的细节将在后面的章节中介绍,其基本思路是每使用一条训练数据时在每一层随机丢弃一般隐藏层神经元,以避免这些神经元之间过强的合作。合作可以很好地拟合训练数据,但是如果测试数据的分布显著不同,那么这些合作就会导致过拟合
此外,AlexNet的成功还得益于其使用GPU进行计算,因为GPU能够高效完成矩阵乘法,到存储器的带宽也很高。随着GPU和CPU技术的发展,以及数据集规模的疯狂增长,深度网络将成为物体识别的不二之选(嗯,现在看来已经成为了现实)
除去ImageNet,还有一些其它应用领域也值得关注。例如,Vlad Mnih使用局部感知野(local field)和多层ReLU单元来从卫星图像上抽取道路,不过他没有用卷积操作
