本系列笔记来自于2017年斯坦福大学Chip Huyen老师所开设的课程CS20SI: TensorFlow for Deep Learning Research。内容基本上来自于课程官网提供的幻灯片和课堂讲义(lecture notes)。一些其它补充内容可能来自于TF官网、知乎相关问答或专栏以及其它网友博客,其中涉及到知乎和其它网友博客的内容我会注明转载来源(尽管可能并不是逐字逐句的)
所有代码片段都隐含了如下两行Python的import语句。笔记制作时使用Python 3.6和TF 1.4
1 | import numpy as np |
以上声明适用于本站中所有以“CS20SI”为标题开头的文章
本课第一讲是绪论性质:前面大概讲解了一些TensorFlow(在不引起歧义的情况下,在本文及后续文章中简称为TF)的背景和发展现状,之后,本课主要讲授了TF中的三个基本概念:张量(tensor)、图(graph)和会话(session)
张量
按照官网的定义,TensorFlow是一种框架,使用它可以定义和运行由张量组成的计算。其中张量是对向量和矩阵的更一般化表示,因为通常情况下,向量是一维的,矩阵是二维的,而计算可能会在更高维空间中进行。TF在内部把张量表示成一个n维数组
这里有一点可能比较容易混淆,就是张量的维数和矩阵的维数实际上是不同的两个概念。所有矩阵,不管其有多少列,有多少行,秩为多少,都是二维张量。不严格地说,如果将一个张量使用print函数打印出来,最左边有多少个连续的左中括号,这个张量就有多少维。例如[[[1, 2], [3, 4]], [[2, 1], [3, 4]]]就是一个三维张量(为了证明这一点,笔者试着使用a = tf.constant([1, [2, 3], [[3, 4], [5, 6]], 7], dtype=np.float32)来声明一个不规则的张量,结果会抛出异常:ValueError: setting an array element with a sequence.)。就像所有二维张量都被称为矩阵一样,一维张量和零维张量也有为人熟知的另一个名字:前者为向量,后者为标量
图与会话
基本操作
前面说到,TF会定义和运行计算,这里其实隐含了TF的一个很核心的设计思想:计算的定义和运行实际上是分开进行的,其“定义”通过图来进行,其“运行”通过会话来进行。图并不做任何计算,也不保存任何值,只定义代码中指明的操作和操作之间的依赖关系。而会话用来执行图所定义的计算(或者执行图中一部分定义的计算),分配资源,保存变量的实际值
TF的所有图都是tf.Graph类的实例。图中的每个顶点都是一个操作(tf.Operation),每条边都是一个张量(tf.Tensor)。尽管如前面所述,TF中所有计算都需要事先定义一个图,但是TF程序自己会维护一个默认的图(default graph),因此在很多情况下不需要开发人员自己手动定义图
下面这段程序虽然简单,但是其也有图与之对应
1 | a = tf.add(3, 5) |
其对应的图为
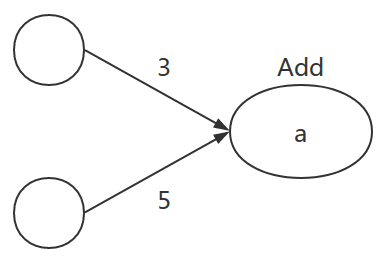
需要注意的是,对于上面这段程序,其输出并不是8,而是
Tensor("Add:0", shape=(), dtype=int32)
这是因为,此时计算图刚刚被定义,而计算是通过会话Session来执行。只有在会话里,才能拿到a的值。更严格地说,Session对象封装了一个环境,在这个环境里执行Operation对象,并计算Tensor对象的值。既然是封装了一个环境,那么它就可能会拥有自己的资源,所以最佳实践是像操作文件那样,也使用上下文管理器(context manager),即一个with语句块来保证在退出语句块时会话所拥有的资源被自动释放(当然也可以不用with,但是代价是需要使用tf.Session.close来显式手动释放资源)
接下来的问题是如何将一个Graph对象和一个Session对象绑定。Session对象初始化时,可以接收一个Graph对象作为参数。但是如果不传递这个参数,则该对象与当前系统默认的图绑定,也只能运行系统默认图中的操作。对于上面定义的计算图,由于使用的是系统默认图,因此可以直接使用如下的方式来运行会话
1 | a = tf.add(3, 5) |
这样,就能输出结果8了
指定设备
默认情况下,开发人员创建的操作会以“最佳匹配”的方式分配到某个物理设备上。比如,假如机器中既有CPU也有GPU,而某个操作有GPU实现,那么TF会让GPU去执行这个操作。当然,也可以手动指定设备,例如
1 | weights = tf.random_normal(...) |
with语句块中的语句就会在第一块GPU上执行。有时,开发人员对任务的手工分配可能并不合理,例如强制指定某个只有CPU实现的操作在GPU上执行,这时可以在初始化tf.Session时指定参数allow_soft_placement为True来矫正这种分配方式。此外,还可以指定参数gpu_options.allow_growth为True来让占用的显存随需增长,避免一上来就把所有可用显存都用完
定义多个计算图
在某些情况下,当需要创建多个计算图时,可以使用如下语法
1 | g = tf.Graph() |
要向自定义的图中加入操作符,需要先把它设置成默认图
1 | g = tf.Graph() |
可以通过如下操作获取当前的默认图
1 | g = tf.get_default_graph() |
需要注意的是,多个计算图一般需要多个会话,而每个会话默认情况下都会试图用尽所有可用资源。另外,如果不使用numpy或者python本身的变量,则不能在两个图之间传递数据。而这种做法在分布式环境下不可用。例如,下面的代码片段会报错:
1 | g = tf.Graph() |
其原因是,变量a是在最开始的默认图中定义,而b是在用户的自定义图中定义,两者分属不同的计算图
课件中始终建议尽量只维护不多于一个计算图。如果需要定义多个图,也尽量先考虑定义成一个图里的两个不相交子图。这里“不多于一个”我个人理解为是默认图+至多一个自定义图。但是在Google给出的NMT例子中,却鼓励定义多个图。究竟哪个才是最佳实践可能还是要依赖于场合
参考资料:
TF文档
https://danijar.com/what-is-a-tensorflow-session/
