动机
本课在很早之前就讲过了感知机的概念,前面又讲过了模型聚合的概念,那么有没有一种方法可以将若干个感知机模型通过线性的方式聚合起来?显然是可以的。假设一共有\(t\)个感知机,每个感知机训练出来的系数为\({\bf w}_t\),返回的模型为\(g_t\),其在整个模型里的权重为\(\alpha_t\),则最后得到的聚合模型\(G\)为 \[ G({\bf x}) = {\rm sign}\left(\sum_{t=1}^T \alpha_t \underbrace{ {\rm sign}({\bf w}_t^\mathsf{T}{\bf x})}_{g_t({\bf x})}\right) \] 可以看到这个过程里有两组权重:第一组\({\bf w}_t\)用来投票,第二组\(\alpha_t\)用来让\(g_t\)投票。另外,这里有两组阶梯函数的输出,一组由每个\(g_t\)产生,一组由最后的\(G\)产生
将感知机聚合以后,可以实现某些布尔函数。下图给出了AND函数的例子
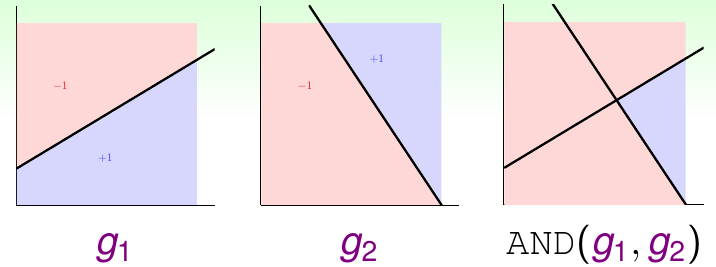
在这种情况下,只有被\(g_1\)和\(g_2\)全部判断为+1的例子,才会被\(G\)判断为+1,否则就会判断为-1。这种分类器不难实现,只需要使得 \[ G({\bf x}) = {\rm sign}(-1 + g_1({\bf x}) + g_2({\bf x})) \] 就可以学习出上图中由两条直线界定出的边界,达到AND函数的效果。同理,OR和NOT的效果也可以用类似的方法产生。实际上,任意多的感知机聚合得到的模型能力非常强大,它可以逼近凸包集合(注意凸包集合的VC维是\(\infty\),是一种能力很强的模型),也可以逼近一个平滑的边界,例如一个圆形的边界
但是,感知机的线性组合不能实现XOR函数,这是一个最大的限制。其本质原因是,如果把\(g_1\)和\(g_2\)看作是特征转换,则在新的空间\(\boldsymbol{\phi}(g_1({\bf x}), g_2({\bf x}))\)中,经过转换的数据集仍然不是线性可分的
那么怎么以感知机为基础去实现XOR函数呢?回顾之前所讲的,非线性可分的数据集可以通过某些变换使其线性可分,这个道理在这里同样适用。将XOR函数转写,有 \[ {\rm XOR}(g_1, g_2) = {\rm OR}({\rm AND}(-g_1, g_2), {\rm AND}(g_1, -g_2)) \] 由于AND函数可以用感知机线性聚合来实现,OR函数也可以用感知机线性聚合来实现,因此通过上面的方法就可以以感知机为基础实现XOR了,只不过此时多了一层。这种更强大的模型称为多层感知机,它是后面提到的所有神经网络的基础
多层感知机实际上是对生物钟神经元工作原理的模拟。这里每个感知机就可以看作是一个神经元,神经元的系数可以看做是神经元之间的连接,系数绝对值越大,连接越强。神经元之间通过连接,就形成了一个网络结构,称为神经网络 。如下就给出了一个多层感知机结构的示意图

上图中每个圆圈就是一个感知机,圆圈上的的折线表示做一个非线性变换(这里是sign函数,折线也是sign函数的图像),圆圈之间的连线以及圆圈与\(x_i\)的连线表示了输入输出关系
神经网络假设集合
如果将每一层感知机做的事情看作是对原始数据的一个变换,记第一层感知机做的变换为\(\boldsymbol{\phi}^{(1)}\),第二层感知机做的变换为\(\boldsymbol{\phi}^{(2)}\),最后大绿色圆对应的感知机实际上就是输出数据结果,记其权重为\(\bf w\),则整个模型可以表示为\(s = {\bf w}^\mathsf{T}\boldsymbol{\phi}^{(2)}(\boldsymbol{\phi}^{(1)}({\bf x}))\)。可见,其外核实际上就是一个线性模型,这个线性模型可以根据要解决的问题选择不同的具体实现,例如线性分类模型(感知机)、线性回归或者Logistic回归。这里为了简单起见,将选取线性回归做线性模型而讲解(即最后一步绿圆圈使用线性回归做输出)
另外,中间的非线性变换是对分数\(s\)的变换。如果这个变换是阶梯状函数(例如sign),那么每个神经元就是一个感知机。可不可以将这个变换函数也做一些修改呢?变成线性函数是不太好的,因为这样会使整个网络退化为一个线性变换(线性变换的线性组合还是线性变换),增加了计算复杂度,但是降低了模型复杂度。实际上,由于阶梯状函数是离散函数,难以最优化,因此通常使用s形函数,尤其是双曲正切函数\(\tanh(x)\),其定义为 \[ \tanh(x) = \frac{\exp(x) - \exp(-x)}{\exp(x) + \exp(-x)} \] 可以把它看作是sign函数的模拟版本,但是更容易最优化,而且更类似于生物中神经元的工作原理
\(\tanh\)函数与之前提到的sigmoid函数也有关系: \[ \tanh(x) = 2\theta(2x) - 1 \] 之后的讲解中,中间的非线性变化会使用\(\tanh\)函数
接下来,为了更好地定义神经网络假设集合,需要对网络中出现的各个权重和得分进行定义。总体可见下图
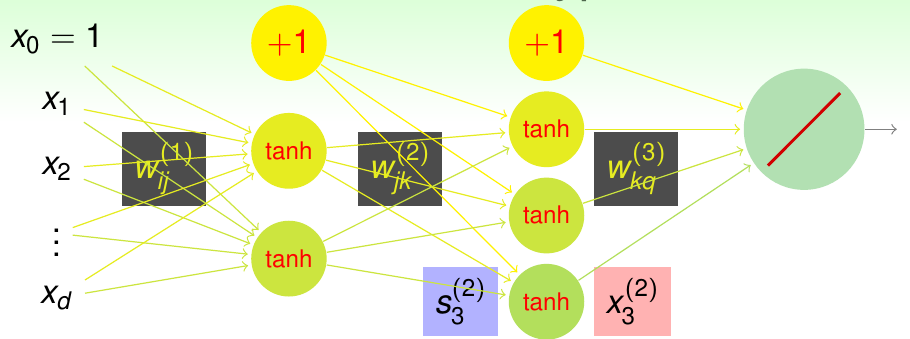
其中,\(L\)代表了神经网络总的层数。输入层记为第0层,第一步变换称为第1层,以此类推。\(d^{(\ell)}\)为网络中第\(\ell\)层所含有的总节点数。神经元之间每个连接其本质是一个权重,可以记为\(w_{ij}^{(\ell)}\),其中\(1 \le \ell \le L\)指明该权重连进第\(\ell\)层;\(0 \le i \le d^{(\ell -1)}\)是第\(\ell - 1\)层神经元的序号,从0开始标记(0对应的是常数项,也就是截距),可以看作是输入索引;\(1 \le j \le d^{(\ell)}\)是第\(\ell\)层神经元的序号,从1开始标记,可以看作是输出索引。换句话说,\(w_{ij}^{(\ell)}\)表示第\(\ell -1\)层第\(i\)个单元指向第\(\ell\)层第\(j\)个单元的权重
第\(\ell\)层中,第\(j\)个节点送进其变换函数之前的值,是上一层所有节点的加权得分总和,记为\(s_j^{(\ell)}\)。由上一段的定义,有 \[ s_j^{(\ell)} = \sum_{i=0}^{d^{(\ell - 1)}} w_{ij}^{(\ell)}x_i^{(\ell-1)} \] 其中\(x_j^{(\ell)}\)是得分经过变换后得到的值(如果\(\ell = 0\),则对应原始数据中的一个特征),有 \[ x_j^{(\ell)} = \begin{cases} \tanh\left(s_j^{(\ell)}\right) & {\rm if\ }\ell < L \\ s_j^{(\ell)} & {\rm if\ }\ell = L\end{cases} \] 称中间使用非线性变换的层为隐含层(更确切地说,是输出结果被其它层当做输入的层),则神经网络假设集合做的事情就是将原始\(\bf x\)作为输入层\({\bf x}^{(0)}\),经过中间隐含层的一系列计算得到\({\bf x}^{(\ell)}\),最后由输出层做预测得到\(x_1^{(L)}\)的过程
从物理意义上看,中间各层实际就是对数据做各种变换\(\boldsymbol{\phi}^{(\ell)}({\bf x})\), \[ \boldsymbol{\phi}^{(\ell)}({\bf x}) = \tanh\left(\left[\begin{array}{c} \sum_{i=0}^{d^{(\ell -1)}} w_{i1}^{(\ell)}x_i^{(\ell - 1)} \\ \vdots\end{array}\right]\right) \] 当\(x\)与\(w\)接近(平行)时,\(wx\)的值更大,\(\tanh\)的结果越接近+1。换句话说,此时\(\bf x\)与权重向量\(\bf w\)在模式上更加匹配。即神经网络中的每一层都在做模式提取,这种模式是跟各层权重吻合的模式
具体的变换方式是从数据中学习得到的,下一节就会介绍具体的学习方法
神经网络学习
前面讲述了神经网络结构中每个权重\(w_{ij}^{(\ell)}\)是怎么产生,那么一个很自然的问题就是,如何学习出最优的\(\{w_{ij}^{(\ell)}\}\),使\(E_{\rm in}\left(w_{ij}^{(\ell)}\right)\)最小。如果只有一个隐藏层,整个神经网络就会退化为感知机的聚合模型,因此可以使用梯度提升来确定隐藏层的权重。但是如果有多个隐藏层,问题就没有这么简单了。但是换一个角度思考,对于每一条输入\({\bf x}_n\),当神经网络确定以后,它的输出就是确定的,记为\({\rm NNet}({\bf x}_n)\),则预测输出的误差也可以确定。由前面的说明,这里使用平方误差衡量,所以误差函数为\(e_n = (y_n - {\rm NNet}({\bf x}_n))^2\),这个值也被称为残差。由于神经网络的输出跟每个权重之间都存在变化关系,因此可以计算\(\frac{\partial e_n}{\partial w_{ij}^{(\ell)}}\),进而可以使用前面讲过的梯度下降法(GD)或者随机梯度下降法(SGD)做最优化。所以接下来要解决的问题,就是如何计算\(\frac{\partial e_n}{\partial w_{ij}^{(\ell)}}\)
首先看一个最简单的情况:对神经网络最后一层中的权重\(w_{ij}^{(L)}\),其与残差之间的关系。注意最后一层只有一个节点,因此\(j\)肯定为1。而且最后一层的节点按照前面的约定仅做一个线性变换,因此其输出就是\(s_1^{(L)}\)。这样一来,可以将残差项展开,即 \[ \begin{align*} e_n &= (y_n - {\rm NNet}({\bf x}_n))^2 = \left(y_n - s_1^{(L)}\right)^2 \\ &= \left(y_n - \sum_{i=0}^{d^{(L-1)}}w_{i1}^{(L)}x_i^{(L-1)}\right)^2 \end{align*} \] 因此,对于神经网络的最外层,要计算\(\frac{\partial e_n}{\partial w_{i1}^{(L)}}\ (0 \le i \le d^{(L-1)})\),可以借助中间变量\(s_1^{(L)}\),使用链式法则 \[ \begin{align*} \frac{\partial e_n}{\partial w_{i1}^{(L)}} = \frac{\partial e_n}{\partial s_1^{(L)}} \cdot \frac{\partial s_1^{(L)}}{\partial w_{i1}^{(L)}} = -2\left(y_n-s_1^{(L)}\right) \cdot \left(x_i^{(L-1)}\right) \end{align*} \] 推而广之,对于前面的隐含层\(\ell, 1 \le \ell < L\),\(\frac{\partial e_n}{\partial w_{ij}^{(\ell)}}\ (0 \le i \le d^{(\ell-1)}; 1 \le j \le d^{(\ell)})\)可以通过类似的方法计算: \[ \frac{\partial e_n}{\partial w_{ij}^{(\ell)}} = \frac{\partial e_n}{\partial s_j^{(\ell)}} \cdot \frac{\partial s_j^{(\ell)}}{\partial w_{ij}^{(\ell)}} \] 其中乘数可以很容易地得到为\(x_i^{(\ell - 1)}\),但是被乘数的计算并不直观。暂且将被乘数记为\(\delta_{j}^{(\ell)}\),上面的式子可以写为 \[ \frac{\partial e_n}{\partial w_{ij}^{(\ell)}} = \frac{\partial e_n}{\partial s_j^{(\ell)}} \cdot \frac{\partial s_j^{(\ell)}}{\partial w_{ij}^{(\ell)}} = \delta_{j}^{(\ell)} \cdot\left(x_i^{(\ell - 1)}\right) \] 当\(j = 1, \ell = L\)时,由上面的推导有\(\delta_1^{(L)} = -2\left(y_n - s_1^{(L)}\right)\)。接下来的任务就是推出其它的\(\delta\)
由于\(\delta\)是最终残差对神经网络中隐藏层某个节点给出的得分的偏导数,因此可以思考这个得分是如何影响残差的。某个节点得到得分\(s_{j}^{(\ell)}\)以后,会对其做非线性变换\(\tanh\),得到节点的输出\(x_j^{(\ell)}\)。这个输出乘以下一层的各个权重\(w_{jk}^{(\ell + 1)}\),得到的是一个向量,向量中的每一维都对应了下一层每个节点的一个输出,即 \[ s_j^{(\ell)}{ \overset{\tanh}{\Longrightarrow}} x_j^{(\ell)} \overset{w_{jk}^{(\ell + 1)}}{\Longrightarrow} \left[\begin{array}{c}s_1^{(\ell + 1)} \\ \vdots \\ s_k^{(\ell + 1)} \\ \vdots \end{array}\right] \Longrightarrow \cdots \Longrightarrow e_n \] 因此求偏导时使用的链式法则里就需要包含\(x_j^{(\ell)}\)和\(s_k^{(\ell + 1)}\)这两组中间变量(其中后一组一共有\(d^{(\ell + 1)}\)个变量)。具体计算,有 \[ \begin{align*} \delta_j^{(\ell)} = \frac{\partial e_n}{\partial s_j^{(\ell)}} &= \sum_{k=1}^{d^{(\ell + 1)}} \frac{\partial e_n}{\partial s_k^{(\ell + 1)}}\cdot \frac{\partial s_k^{(\ell + 1)}}{\partial x_j^{(\ell)}} \cdot \frac{\partial x_j^{(\ell)}}{\partial s_j^{(\ell)}} \\ &= \sum_k \left(\delta_k^{(\ell + 1)}\right)\left(w_{jk}^{(\ell + 1)}\right)\left(\tanh'\left(s_j^{(\ell)}\right)\right) \end{align*} \] 因此,第\(\ell\)层的\(\delta_j^{(\ell)}\)可以从第\(\ell + 1\)层的\(\delta_{k}^{(\ell + 1)}\)推出。将以上推导汇总起来,就可以得到神经网络的学习算法,称为反向传播算法,其具体过程为
初始化所有权重\(w_{ij}^{(\ell)}\)
在时刻\(t=0,1,\ldots ,T\)
- 随机选取某个\(n \in \{1,2,\ldots, N\}\)
- 正向:计算所有\(x_i^{(\ell)}\),其中\({\bf x}^{(0)} = {\bf x}_n\)
- 反向:计算所有\(\delta_j^{(\ell)}\)
- 梯度下降:\(w_{ij}^{(\ell)} = w_{ij}^{(\ell)} - \eta x_i^{(\ell - 1)}\delta_j^{(\ell)}\)
返回\(g_{\rm NNET}({\bf x}) = \left(\cdots \tanh\left(\sum_j w_{jk}^{(2)} \cdot \tanh \left(\sum_i w_{ij}^{(1)}x_i\right)\right)\right)\)
注意有时第1步到第3步是并行地执行很多次,然后将得到的所有数值求出平均\(\left(x_i^{(\ell - 1)} \delta_j^{(\ell)}\right)\)来在第4步更新权重。这种方法介于GD和SGD之间,称为mini-batch GD
优化与正则化
前面讲解神经网络反向传播算法时,使用的误差函数是平方误差函数。将这种情况推广,可以知道神经网络一般是要最小化如下的\(E_{\rm in}\) \[ E_{\rm in}({\bf w}) = \frac{1}{N}\sum_{n=1}^N {\rm err} \left(\left(\cdots \tanh\left(\sum_j w_{jk}^{(2)} \cdot \tanh \left(\sum_i w_{ij}^{(1)}x_i\right)\right)\right), y_n\right) \] 但是,当有多个隐藏层存在时,这通常不是一个凸优化问题,GD/SGD很难找到全局最优解,只能找到局部最优解。而且,对\(w_{ij}^{(\ell)}\)不同的初始化可能会达到不同的局部最优解,而且并不知道如何初始化能让最后得到的解更好。但是,根据经验,大的初始权重会使得\(\tanh\)函数的值变得很大,导致梯度(变化量)很小,出现饱和(saturate)现象。因此,一般都是用一些随机的,小的值做初始权重
神经网络是一种很强大的算法。假设\(V\)是神经元的数目,\(D\)是神经网络中权重的数目(也就是神经元之间连接的数目),那么整个神经网络的VC维约为\(O(VD)\)。当\(V\)很大时,神经网络几乎可以模拟任意函数,但是也就更容易过拟合
神经网络避免过拟合有一种很基本,也可以看作是“老朋友”的方法,就是加入正则化。直观的方法是加入L2正则化项\(\Omega({\bf w}) = \sum\left(w_{ij}^{(\ell)}\right)^2\),但是这种权重缩减方法的结果是,大的权重缩减得大,小的权重缩减得小,最后哪个权重都没有缩减到0。而这里做正则化的目的是希望得到稀疏的\(\bf w\),也就是让尽量多的\(w_{ij}^{(\ell)}\)为0,这样才能有效地减小整个神经网络的VC维。提到使权重稀疏的正则化方法,另一个老朋友是L1正则化\(\sum \left|w_{ij}^{(\ell)}\right|\),但是这个正则化项是不可微的,而反向传播是微分导向的算法,因此不能使用L1正则化
通常情况下,神经网络里使用了一种称为“权重淘汰”(weight-elimination)的方法,其实质是一种加权的L2正则化,它将大的权重和小的权重都缩减相同的大小,这样小的权重就会被缩减到0。权重淘汰正则项的形式为 \[ \sum \frac{\left(w_{ij}^{(\ell)}\right)^2}{1+\left(w_{ij}^{(\ell)}\right)^2} \] 神经网络里其实还有一种自己独有的正则化机制,称为“提前停止”法。由于神经网络算法的核心还是GD/SGD,而这种算法随着迭代次数的增多,其在各种不同的\(w\)里选择得越多。如果降低这种算法的迭代次数,它看过的\(w\)就会更少。因此,迭代次数多,有效的VC维就大;反之,迭代次数少,有效的VC维就小。这意味着比较小的迭代次数可以有效降低VC维,而合适的迭代次数可以使用前面讲过的验证法做判断。这种方法对所有基于GD/SGD的算法都适用
